
5-pandas数据基础操作

5.pandas数据基础操作
对一个数据对象进行操作,我们一般都是从【增】、【删】、【改】、【查】 这四个方面入手,了解这四个方面的基本用法,就能使用该数据对象应对大部分情况了。
5.1 pandas 创建数据
5.1.1 pandas 创建 Series
通过列表创建 Series
import pandas as pd
s = pd.Series([1, 2, 3, 4])
print(s)输出如下:

通过字典创建 Series
import pandas as pd
s = pd.Series({'a': 1, 'b': 2, 'c': 3, 'd': 4})
print(s)输出如下:

通过numpy数组创建 Series
import pandas as pd
import numpy as np
s = pd.Series(np.arange(1, 5))
print(s)输出如下:

通过标量创建 Series
import pandas as pd
s = pd.Series(5, index=['a', 'b', 'c', 'd'])
print(s)输出如下:

5.1.2 pandas 创建 DataFrame
通过列表创建 DataFrame
import pandas as pd
df = pd.DataFrame([[1, 2, 3], [4, 5, 6]])
print(df)输出如下:

通过字典创建 DataFrame
import pandas as pd
df = pd.DataFrame({'a': [1, 2, 3], 'b': [4, 5, 6]})
print(df)输出如下:

通过numpy数组创建 DataFrame
import pandas as pd
import numpy as np
df = pd.DataFrame(np.arange(1, 7).reshape(2, 3))
print(df)输出如下:

通过标量创建 DataFrame
import pandas as pd
df = pd.DataFrame(5, index=['a', 'b', 'c'], columns=['d', 'e', 'f'])
print(df)输出如下:

5.2 索引操作
之前在介绍pandas中的数据对象的时候,介绍过 Index 对象,这里先简要简介一下对于 Index 的一些操作。
需要注意的是,这里介绍的是 DataFrame 对象对于 Index 的操作,而不是 Index 本身的操作方法,关于 Index 本身的一些操作,可以去查询官方文档,我们这里还是着眼于 DataFrame 对象的操作。
5.2.1 创建索引
set_index
官方文档链接: set_index
import numpy as np |
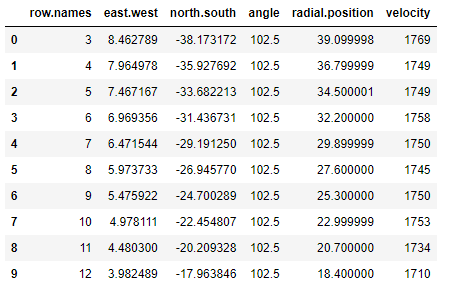
使用 set_index 方法可以将一列 Series 数据作为 Index:
# set_index 将数据中的某一列设置为 index |
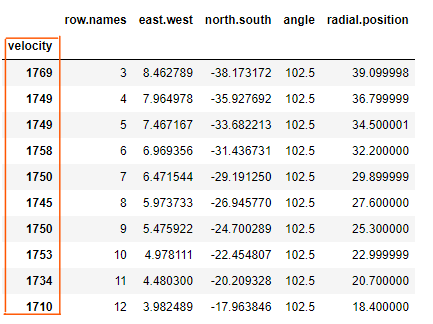
该方法甚至可以设置多层 Index:
# 可以设置多层索引 |
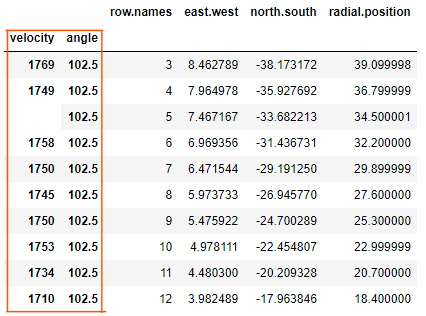
在上面选择 Series 数据作为 Index 时,列名本身(如’velocity’, ‘angle’)就成为 Index 名,即 Index的name属性。
当然也可以不使用用原始数据中本来就有的 Series 数据,而使用自己创建的 Series 数据:
# 自己生成一个Series并将其设置为索引 |
因为我们自己创建的这个 Series 没有指定 name,所以此时 Index 的name也就为空。
在上面使用 set_index 方法选择 DataFrame 中原有的 Series 作为 Index 时,会自动将原来的 Series 列删除,(或者可以理解为直接移动到 Index 去),如果不想删除,可以使用参数 drop=False:
df2=df.set_index(['velocity'], drop=False) |
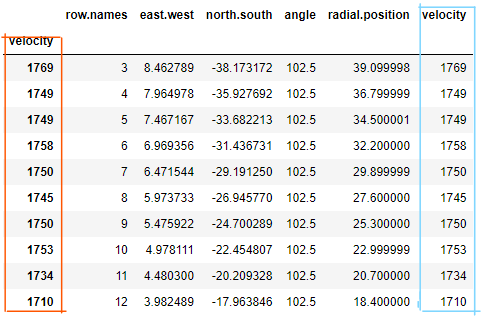
上面说到 Index 不止可以设置一层,还可以设置多层,所以如果原来已经有 Index,其实可以采用“追加”的方式,将新的 Index 添加到原来的 Index 后面去;比如原来默认的 Index 是 [0, 1, 2, … 10],现在想将 velocity 作为 Index 追加上去:
df2=df.set_index(['velocity'], append=True) |
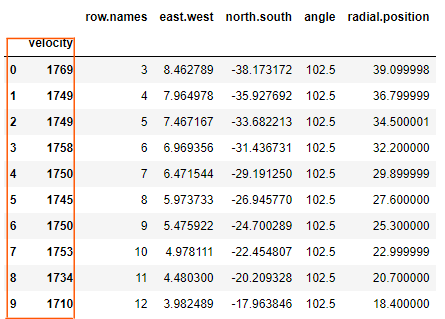
上面对于 df 的索引操作都不会直接修改 原始df,除非添加参数 inplace=True, 但是这样会直接修改原始数据;在数据处理中,一般应该尽量避免直接修改原始数据,所以上面都是先将df修改后的结果存入新的DataFrame,即df2,中再展示。
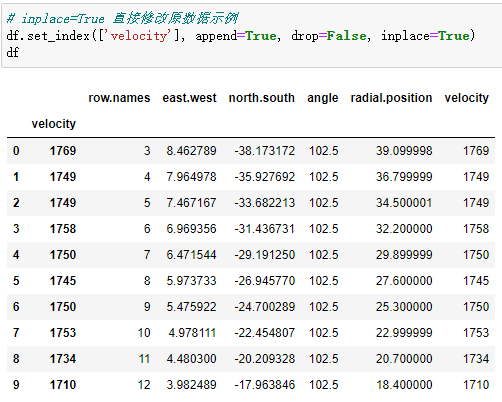
# 直接修改原数据示例 |
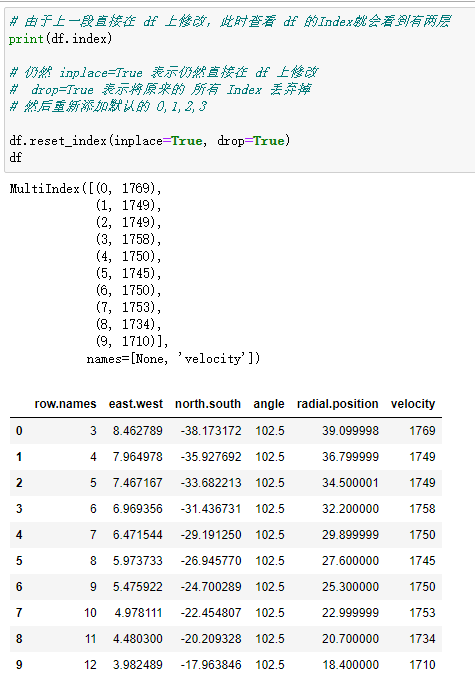
如果要重置 Index,可以使用 reset_index 方法:
官方文档链接:reset_index
# 由于上一段直接在 df 上修改,此时查看 df 的 Index 就会看到有两层 |
关于 set_index 和 reset_index 这两个方法的简单用法就介绍到这里,更详细的用法建议参考官方文档。
5.2.2 修改索引
rename_axis
官方文档链接:rename_axis
要注意,这个修改的是 Index 或 Columns 的名字,即它们的name属性,而不是它们具体的值;比如:
# axis参数默认为0, 表示修改的是 Index 本身的 name
df2 = df.rename_axis('row_num')
print("the name of index: %s" % df2.index.name) # 查看 index 的 name
# df2 的index 的名字 'row_num' 位置要比 columns 矮一层!
print(df2)
# axis参数设置为1, 表示修改的是 columns 的name
df2 = df2.rename_axis('information', axis=1)
print("the name of columns: %s" % df2.columns.name) # 查看 columns 的 name
# columns 的名字 'information' 的位置 和 columns 是同一水平线
print(df2)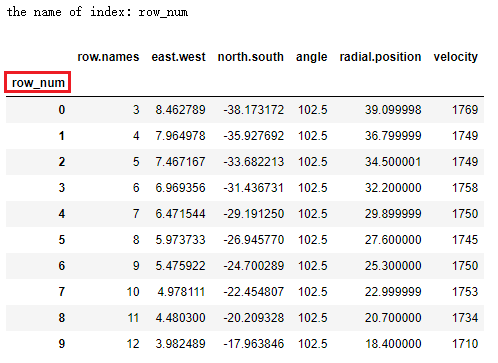
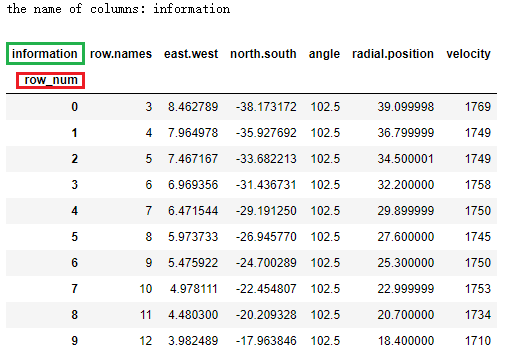
查看修改 index 和 columns 后的详细结果:
# 查看 df2 的 index 和 columns 的具体信息
print(" index具体信息:\n", df2.index)
print("\n columns具体信息:\n", df2.columns)
# 可以看到其中 name 部分已经是我们修改后的内容,而具体的值并没有变
<img src='https://teeyohuang.github.io/pic_bed/Pandas_Base/5_2_2_3.png' width=58%>
rename
官方文档链接:rename
这个就是修改 index 或者 columns 具体的值。给定一个字典,键是原名称,值是想要修改的名称,比如:
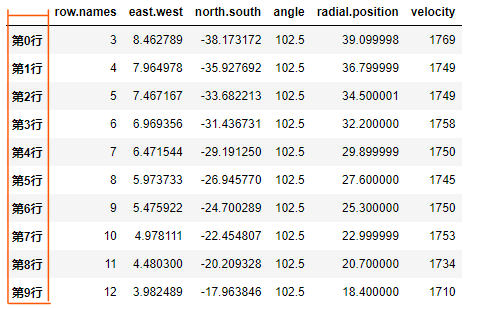
# 以字典的方式准备好新 index 的具体内容
new_index = dict([ (i, f"第{i}行") for i in df2.index])
# 查看该字典,会发现每一个 具体的index,都对应了一个新的值
print("准备要替换为: \n" , new_index)
# 使用rename进行修改,axis参数默认为0, 表示修改 index的内容
df3 = df2.rename(new_index)
print("\n修改后的index.values 信息 \n", df3.index.values)
print(df3)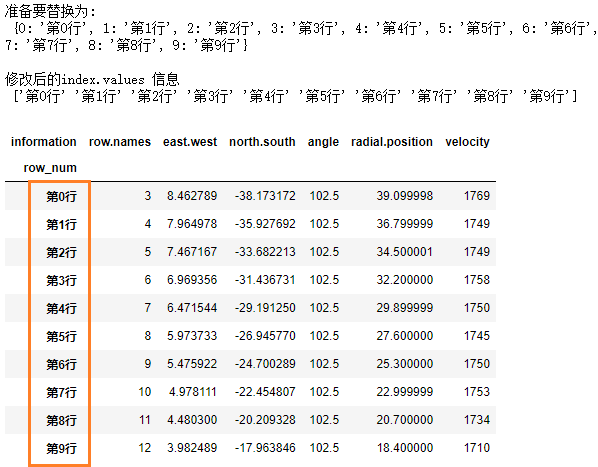
# 以字典的方式准备好新 columns 的具体内容
new_cols = dict([ (col, col.split('.')[-1]) for col in df2.columns])
# 查看该字典,会发现每一个 具体的 col,都对应了一个新的值
print("准备要替换为: \n" , new_cols)
# 使用rename进行修改,axis设置为1, 表示修改 columns 的内容
df3 = df2.rename(new_cols, axis=1)
print("\n修改后的 columns.values 信息 \n", df3.columns.values)
print(df3)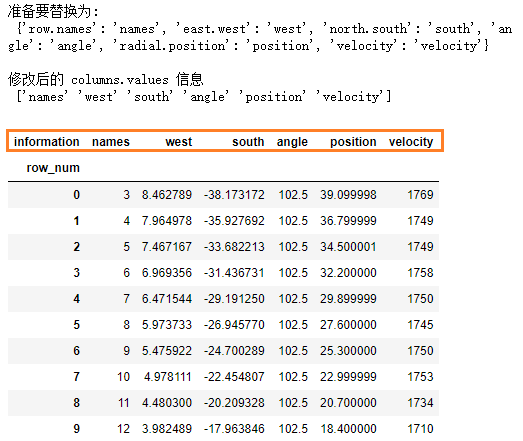
set_axis
官方文档链接:set_axis
用法和 rename 很相似,只不过不用传入字典,可以传入一个列表,然后依次分配即可。下面以修改列名为例子:
new_cols2 = ['Name', 'EW', 'NS', 'Ang', 'Pos', 'Vel'] # 列表形式
df3 = df2.set_axis(new_cols2, axis=1) # 指定 axis=1
print(df3)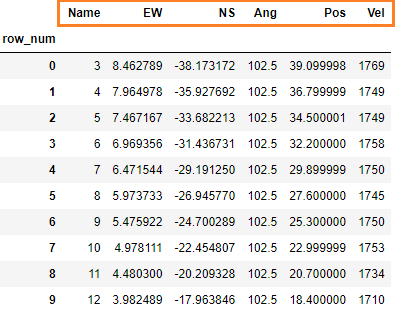
但要注意,set_axis方法会删除原有轴标签的名称(name),如果希望要有名称,只需要重新指定一下即可。
5.3 数据的增删改查操作
在使用 pandas 处理数据时,基本都是通过 DataFrame 对象来装载数据的,所以下面将介绍如何使用 DataFrame 数据对象自带的一些方法,对于数据的一些基础性的增删改查操作。
5.3.1 查询
本小节以机器学习领域的公开数据集 wine dataset (葡萄酒数据集) 为例介绍如何对DataFrame数据进行查询。以下实例虽然是针对 DataFrame 对象,但是大部分操作同样适用于 Series 对象。
# 这里使用一个公开的机器学习数据集: wine dataset (葡萄酒质量) |

5.3.1.1 简单信息查询
-
查看该对象的类型,以及有多少行,多少列,每列的名称、类型,占用的内存等等信息,相当于是对于该 DataFrame 的一个宏观上的描述。
df.info()

-
查看该 DataFrame 对象有多少行,多少列,返回一个元组: (行数,列数)
df.shape
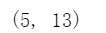
-
查看前 n 行的数据,n默认值为5。
df.head(2)

-
查看倒数 n 行的数据,n默认值为5。
df.tail(2)

-
查看该 DataFrame 对象每一列的数据类型。
df.dtypes

-
返回一个 numpy array,存放的是 DataFrame 的数据部分;
更推荐使用 DataFrame.to_numpy()df.values
# 更推荐使用 df.to_numpy()
-
从数据中随机采样出 n 条数据。可接收参数有:
n: 指定采样的行数,默认为1。
frac: 指定采样比例,默认为1。(n 和 frac 二选一,一个是指定多少条,一个是指定采多少比例)
replace: 是否放回,默认为False。
weights: 指定权重,默认为None。
random_state: 随机数种子,默认为None。
axis: 指定轴,默认为0,即抽样行数据;axis=1 时 抽样列数据。
ignore_index: 是否忽略原来的索引,默认为False。# axis 默认为0,表示采样行数据
df.sample(2)
# axis 为1,表示采样列数据
df.sample(2, axis=1)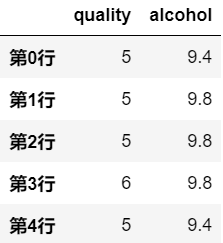
# 采用 比例 采样
df.sample(frac=0.2, axis=1)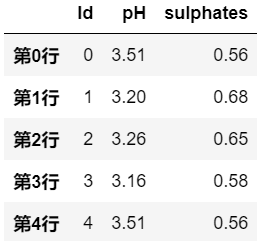
此外,还有一些查看 DataFrame 其它基本信息的方法或者属性,举例如下:
| 方法或属性 | 作用 |
|---|---|
| DataFrame.axes | 返回一个列表,列表内容为 [列名, 行名] |
| DataFrame.index | 返回一个 Index 对象,内容为行名 |
| DataFrame.columns | 返回一个 Index 对象,内容为列名 |
| DataFrame.keys() | 返回一个 Index 对象,内容为行名(对于Series) 或者 列名(对于DataFrame) |
| DataFrame.size | 返回元素的总个数(行数*列数) |
| DataFrame.ndim | 返回数据的维度 |
5.3.1.2 数据查询
本小节介绍如何对 DataFrame 中的数据进行查询 ,包括行、列的查询,以及数据值的查询。
列索引查询
- 采用
df[列名]的方式,可以查询 DataFrame 中的某一列,返回的是一个 Series 对象。 采用
df.列名的方式,可以查询 DataFrame 中的某一列,返回的是一个 Series 对象。# 按照索引取数
print('方法一\n', df['pH'])
print('\n方法二\n',df.pH)
- 采用
多列数据查询
采用
df[[列名1, 列名2, ...]]的方式,可以查询 DataFrame 中的多列,返回的是一个DataFrame 对象。# 取多列数据
print(df[['pH','alcohol']])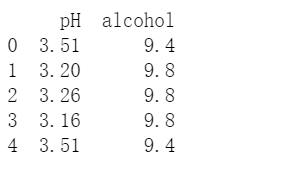
要注意,df[列名]返回的是 Series对象,因为这个操作就是在取列数据;
df[[列名]] 返回的是 DataFrame对象,就算只填一个列名,那也是看作一个只有一列的 DataFrame.# 注意这两种情况的区别:
print(type(df['pH'])) # 返回的是一个 Series 对象
print(type(df[['pH']])) # 返回的是一个 DataFrame 对象
按照 python 切片逻辑取多行数据
这种切片操作是将每一行数据视为一个元素来取
# 按照python 切片逻辑取多行数据
df[1:3]
使用loc轴标签取数据
取列数据:
df.loc[:, 列名]
返回一个 Series 对象# 轴标签取数据
# 1.取列数据-> Series
print('1.按照轴标签 loc 取列数据:')
print(df.loc[:, 'pH'])
print(type(df.loc[:, 'pH']))
取行数据:
df.loc[ 行名 ]返回行数据,但是也会转化成一个 Series 对象
# 2.取行数据-> Series
print('\n\n2.按照轴标签 loc 取行数据:')
print(df.loc['第1行'])
print(type(df.loc['第1行']))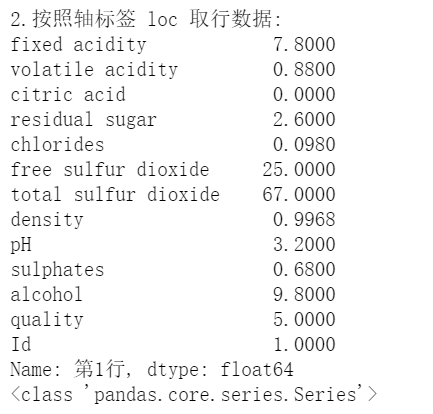
取单个数据:
df.loc[行名, 列名]返回具体的数据
# 3.取单个元素->
print('\n\n3.按照轴标签 loc 取单个数据:')
print(df.loc['第1行', 'pH'])
print(type(df.loc['第1行', 'pH']))
取一行多列数据:
df.loc[行名, [列名1, 列名2, ...]]
返回一个 Series 对象# 4.取某一行的多列数据-> Series
print('\n\n4.按照轴标签 loc取多列的某一行数据:')
print(df.loc['第1行', ['pH', 'alcohol']])
print(type(df.loc['第1行', ['pH', 'alcohol']]))
取多行一列数据:
df.loc[[行名1, 行名2, ...], 列名]
返回一个 Series 对象# 5.取多行的某一列数据-> Series
print('\n\n5.按照轴标签 loc取多行的某一列数据:')
print(df.loc[['第1行', '第2行'], 'pH'])
print(type(df.loc[['第1行', '第2行'], 'pH']))
取多行多列数据:
df.loc[ [ 行名1, 行名2, ...], [列名1, 列名2, ...] ]
返回一个 DataFrame 对象(相当于原DataFrame的一个子集)# 6.取多行的多列数据-> DataFrame
print('\n\n6.按照轴标签 loc取多行多列数据:')
print(df.loc[['第1行', '第2行'], ['pH', 'alcohol']])
print(type(df.loc[['第1行', '第2行'], ['pH', 'alcohol']]))
使用iloc轴序号取数据
取列数据:
df.iloc[:, col_j]
返回一个 Series 对象# 1.取列数据-> Series
print('1.按照轴序号 iloc 取列数据:')
print(df.iloc[:,3])
print(type(df.iloc[:, 3]))
取行数据:
df.iloc[ row_i ]返回行数据,但是也会转化成一个 Series 对象
# 2.取行数据-> Series
print('\n\n2.按照轴序号 iloc 取行数据:')
print(df.iloc[1])
print(type(df.iloc[1]))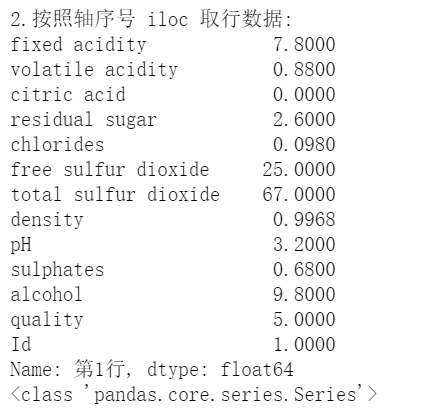
取单个数据:
df.iloc[row_i, col_j]返回具体的数据
# 3.取单个元素->
print('\n\n3.按照轴序号 iloc 取单个数据:')
print(df.iloc[1, 3])
print(type(df.iloc[1, 3]))
取一行多列数据:
df.iloc[row_i, [col_j1, col_j2, ...]]返回一个 Series 对象;
实际上,列序号部分也可以用python切片方式表达 [col_m : col_n]# 4.取某一行的多列数据-> Series
print('\n\n4.按照轴序号 iloc 取多列的某一行数据:')
print(df.iloc[1, [3,4,5,6]]) # 也可以写为 df.iloc[1, 3:7]
# print(df.iloc[1, 3:7]) # 注意右边界不取
print(type(df.iloc[1, [3,4,5,6]]))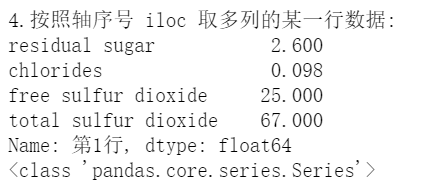
取多行一列数据:
df.iloc[[row_i1, row_i2, ...], col_j]返回一个 Series 对象;
实际上,行序号部分也可以用python切片方式表达 [row_m : row_n]# 5.取多行的某一列数据-> Series
print('\n\n5.按照轴序号 iloc 取多行的某一列数据:')
print(df.iloc[[1,2,3], 3]) # 也可以写为 df.iloc[1:4, 3]
# print(df.iloc[1:4, 3]) # 注意右边界不取
print(type(df.iloc[[1,2,3], 3]))
取多行多列数据:
df.iloc[ [row_i1, row_i2, ...], [col_j1, col_j2, ...]]返回一个 DataFrame 对象
# 6.取多行多列数据-> DataFrame
print('\n\n6.按照轴序号 iloc 取多行多列数据:')
print(df.iloc[[1,2,3], [3,4,5,6]]) # 也可以写为 df.iloc[1:4, 3:7]
# print(df.iloc[1:4, 3:7]) # 注意右边界不取
print(type(df.iloc[[1,2,3], [3,4,5,6]]))
-
# 使用 at + 标签 取具体值
print(df.at['第1行', 'pH'])
# 使用 iat + 序号 取具体值
print(df.iat[1, 3]) 使用 get 取列数据
这是将 DataFrame 视为一个元素为 列数据的字典,上面也讲过,使用
df.keys()可以获得列名,所以这里如果将列名视为字典的 key,则 字典的值就是对应的 Series 值。此外,该方法还能设置 默认值,即如果 get 找不到对应的列名,就返回默认值。
df.get('pH')
使用 truncate 截取中间的数据。
前面提到,
head方法是取头部数据,tail方法是取尾部数据,truncate可以用来取中间数据。但是要注意,它要求 行排列,或者 列排列 是有序的
# 截取中间的 行数据
df.truncate(before='第1行', after='第3行',axis=0)
# 尝试截取中间的列数据
df.truncate(before='fixed acidity', after='residual sugar', axis=1)
# 会报错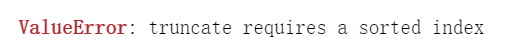
因为数据的列名其实看不出啥顺序出来。
5.3.2 新增
在这一部分,主要讲一下如何执行新增列数据和新增行数据的简单操作,示例数据仍采用上面的 wine dataset,只不过不用取全部的列数据,少取一点便于展示。
# nrows=6 表示仅仅读取前6行, 并且只使用 usecols 来限定只取部分列数据 |
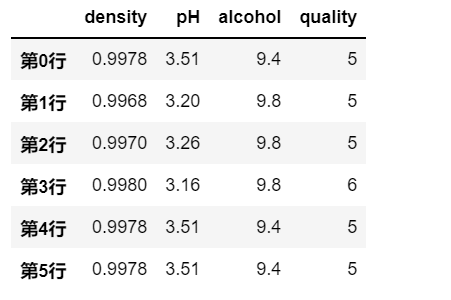
5.3.2.1 新增列数据
df[新列名]
对于一个已经存在的DataFrame对象df,可以直接使用
要注意的是,这种操作相当于 inplace=True ,即会对原始数据 df 进行修改。 同时,如果已经存在该列名,则会覆盖原始列数据。df[新列名]来创建一个新列,新列可以是一个常量值,所有行都为此值;也可以是一个同等长度的序列数据。# 添加一个同等长度的序列数据
df['No.'] = [ i for i in range(len(df))]
print(df)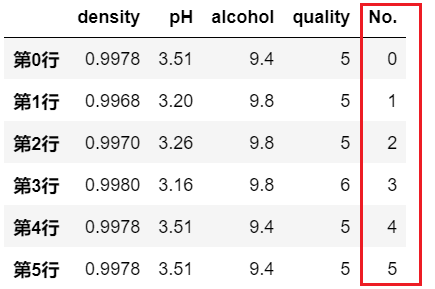
df.loc[:,新列名]
和上面的方法类似,本质上就是通过访问列名的方式来创建新列。
要注意的是,这种操作相当于 inplace=True ,即会对原始数据 df 进行修改。 同时,如果已经存在该列名,则会覆盖原始列数据。# 以一个常数值作为新列
df.loc[:,'DataSet'] = 'WineData'
print(df)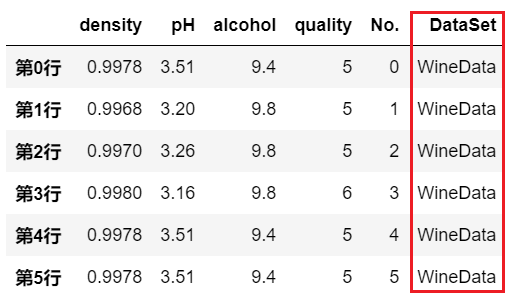
df.insert(位置, 新列名, 新列值)
官网文档:insert
要注意的是,这种操作相当于 inplace=True ,即会对原始数据 df 进行修改。 一般是不允许出现同名列,除非改动参数 allow_duplicates=True,但一般不建议这么搞。# 在序号0位置添加新的一列
df.insert(0,'New_0_col', 2023)
print(df)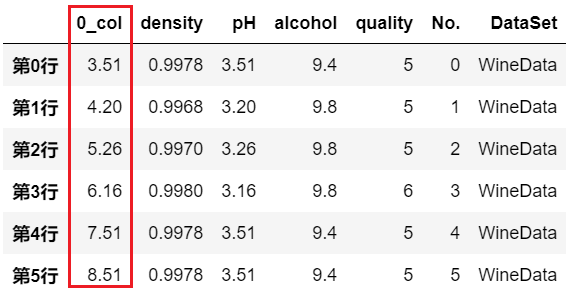
df.assign(新列名=新列值)
官网文档:assign
参数中的新列名不需要写成字符串格式,直接写列名即可;
要注意的是,这种操作相当并不会对原始数据 df 进行修改,它返回的是一个新的 DateFrame 对象。 同时,如果已经存在该列名,则会覆盖原始列数据。
参数中的新列值是一个与原数据同索引的Series,不然会报错。# 指定的 value 一定要是一个与原df的index相同的 Series
print(df.assign(assign_col=pd.Series([1, 2, 3, 4,5,6], index=df.index)))
print('\n原始df未变化:\n',df)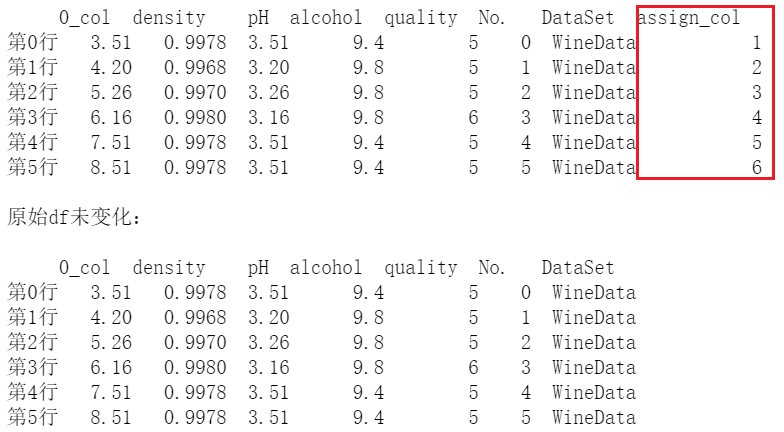
df.eval()
官网文档:eval
eval()可以接受一个表达式,用来创建一个新列,但是也不会对原数数据进行修改,它返回的是一个新的 DateFrame 对象。
# 使用 eval 加上表达式示例
print(df.eval('eval_test = density + pH'))
print('\n原始df未变化:\n')
print(df)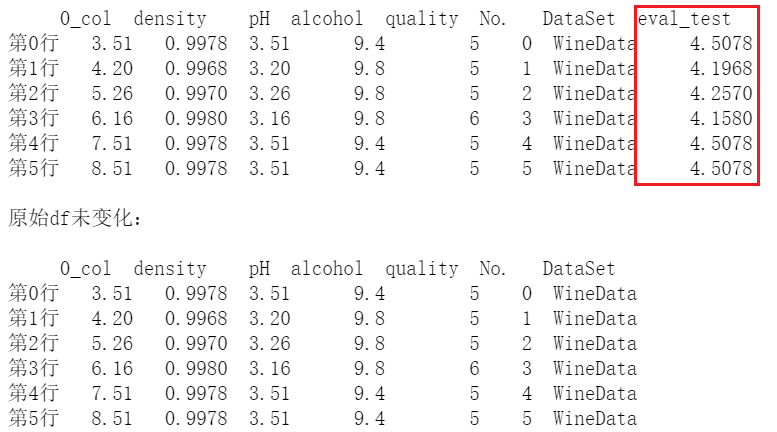
5.3.2.2 新增行数据
df.loc[序号]=新行数据
这个本质也是使用访问数据的方式,在访问时直接进行修改,所以,设原始df一共有N行数据:
- 如果序号取 0~N-1 之间的值,则相当于在原数据上进行修改;
- 如果序号取 N ,则相当于在原数据上进行新增一行;
如果序号取 大于N,就会报错。
# 使用 df.loc[序号] 来增加新行
# 使用常数值来充当新行数据
df.loc[df.shape[0]] = 2
# 使用与列名对应的字典来充当新行数据
df.loc[len(df)] = {'0_col':11, 'density':22, 'pH':33, 'alcohol':44, 'quality':55, 'No.':66, 'DataSet':77}
print(df)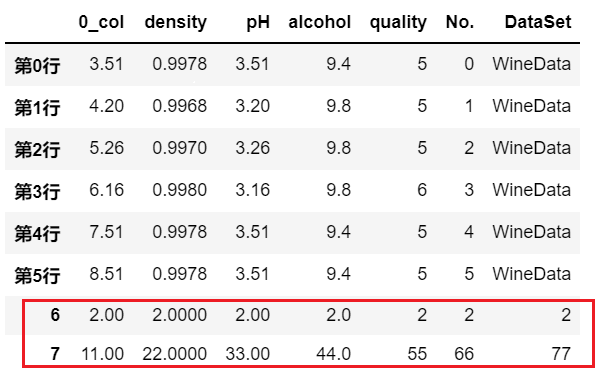
df.append(新行数据)
官网文档:append
这个方法在 pandas 1.4 版本后就被废弃了,但是考虑到有些环境下用的并不是最新版本的pandas,所以这里还是讲一下。
append 可以接受字典类型的数据,字典中应为 {列名1:列值1,…} 这样的形式,表示新的一行每个列的位置应该填充什么数据(缺失列名会填充NAN),这样就可以在尾部新增一行数据了。
# 使用 df.append() 来增加新行
df.append({'0_col':11, 'density':22, 'pH':33, 'alcohol':44, 'quality':55, 'No.':66, 'DataSet':77})append()也可以接收一个DataFrame 对象,这样就可以在尾部新增多行数据了。- 如果该 DataFrame 对象中没有与df中列名相同的列,则新增加的列名会自动填充为NAN;
- 如果该 DataFrame 对象中有与df中列名相同的列,则新增加的列会填充为该列的数据。
如果该 DataFrame 对象的列名全部不一样,但是列数是一样的,且列的左右顺序也一样,就可以设置 ignore_index=False ,这样就不会考虑列名对应,而是从左往右的顺序依次填充即可。
由于我使用的 pandas 的版本已经没有这个
append方法了,所以就不在这里展示示例结果。
pandas.concat([df1,df2,…])
官网文档:concat
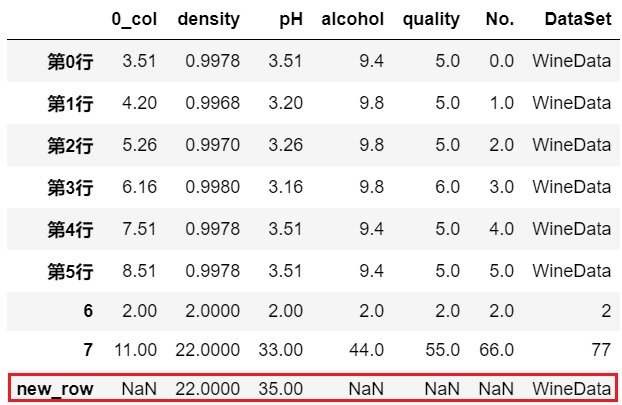
拼接操作并不在原始数据上进行修改,而是返回一个新的 DataFrame 对象。concat()方法可以接收一个或多个 DataFrame 对象,然后将多个 DataFrame 对象拼接在一起。但是它不像append()那样可以接收字典类型的数据,所以如果我们想要增加行,就得先使用行数据创建一个新的 DataFrame 对象,再使用concat()方法拼接。new_row = pd.DataFrame([[22, 35, 'WineData']] ,columns=['density', 'pH', 'DataSet'], index=['new_row'])
print(new_row)
# axis 默认为 0, 表示竖着按行连接
pd.concat([df,new_row])没找到对应的列名就填充 NAN
5.3.3 删除
-
pop()方法可以删除指定列,并返回该列的数据。且会修改原数据。print(df.pop('0_col'))

-
drop()方法可以删除指定列或者行(配合对应的axis),并返回删除后的 DataFrame 对象。inplace默认为False,即不修改原始数据,当其设置为True时就会修改原始数据。
# 删除 index 为 6, 7 的两行
df.drop([6,7], inplace=True) # axis 默认为0
print(df)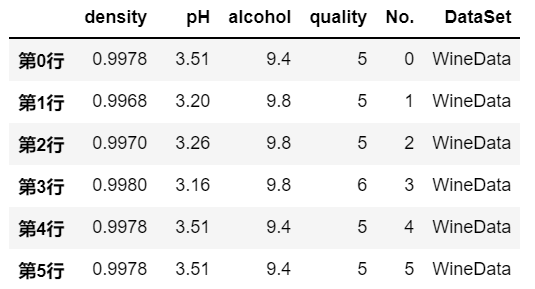
# 删除 columns 为 No. DataSet 的两列
df.drop(['No.','DataSet'], axis=1, inplace=True)
print(df)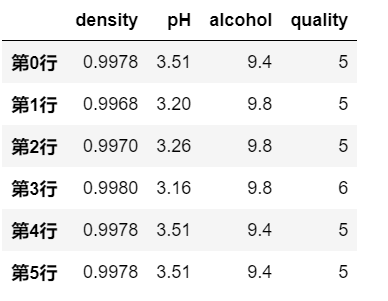
-
该方法是用来删除有空值、有缺失的数据。
参数说明:axis:默认为 0,表示删除有空值的行; 设置为 1 表示删除有空值的列。how:默认为 ‘any’,表示只要出现一个空值,就删除含有空值的行或列;设置为’all’ 表示只有当一行/一列全部为空值的时候才删除该行/列。thresh:默认为 None,表示删除含有空值的行或列的数量大于等于 thresh 的行或列;不与how参数 同时使用。subset:默认为 None,表示删除含有空值的行或列时,只考虑指定的范围。inplace:默认为 False,表示不修改原始数据,当其设置为 True 时,表示修改原始数据。ignore
5.3.4 修改
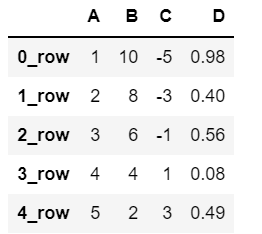
创建一个新的示例 DataFrame
# 再新创建一个示例 DataFrame |
5.3.4.1 按照查询的方式修改
df.loc[行索引,列索引]方式上面介绍过,通过这种
loc取轴标签的形式可以访问 DataFrame 的数据;
如果在访问时赋值,则就会修改原始数据:# df.loc[行索引,列索引] 方式进行修改
df2.loc['0_row','A'] = 10 # 将 (0_row, A) 位置的值改为 10
df2.loc['1_row'] = 1 # 将 1_row 这一行的所有值改为1
df2.loc[:, 'D'] = 4 # 将 D 列的所有值改为 4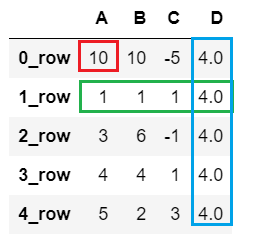
df.iloc[行序号,列序号]方式上面介绍过,通过这种
loc取轴序号的形式可以访问 DataFrame 的数据;
如果在访问时赋值,则就会修改原始数据:# df.loc[行序号,列序号] 方式进行修改
df2.iloc[0,0] = 99 # 将 (0, 0) 位置的值改为 99
df2.iloc[1] = 100 # 将 序号为1 这一行的所有值改为100
df2.iloc[:, 3] = -1 # 将 序号为3 列的所有值改为 -1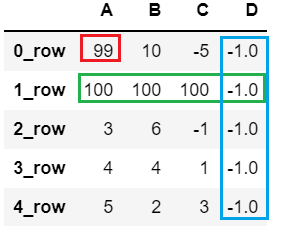
-
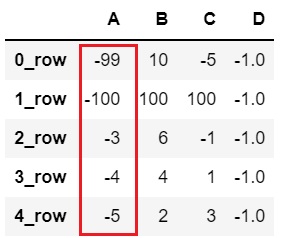
上面介绍过,使用 eval 可以添加新的列数据,同样,eval 也可以用来修改数据,即在eval 的表达式中出现已经存在的列名,并设置 inplace=True 就会修改原始列的数据:
df2.eval('A = A*D', inplace=True) # 要修改原始数据时,要设置 inplace=True
5.3.4.2 批量替换
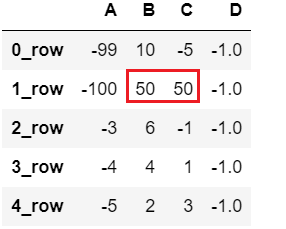
可以将 DataFrame 中的数据批量替换,df.replace(old, new, inplace=False)
# 要修改原始数据时,要设置 inplace=True |
5.3.4.3 填充空值
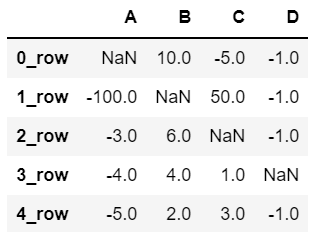
先在 df2 中添加几个空值作为示例 :
# 先填充4个空值 |
-
fillna 使用传入的值对空值进行填充,inplace默认为False,即不修改原始数据
df3 = df2.fillna(2.1)
print('对所有空值用 2.1 填充: \n', df3)
df4 = df2.fillna(2.1, limit=2)
print('\n对靠前的2个空值用 2.1 填充: \n', df4)
df5 = df2.fillna({'A':1, 'B':2, 'C':3, 'D':4})
print('\n对每个列的空值单独设置不同的填充值: \n', df5)
-
bfill 表示向后填充,即从后往前填充,inplace默认为False,即不修改原始数据
print('\n填充前的数据: \n', df2)
df6=df2.bfill()
print('\n对所有空值使用后一行的值填充: \n', df6)
df7=df2.bfill(axis=1)
print('\n对所有空值使用后一列的值填充: \n', df7)
print('最后一列没有后一列,所以最后一列无法得到填充,仍然是 NAN')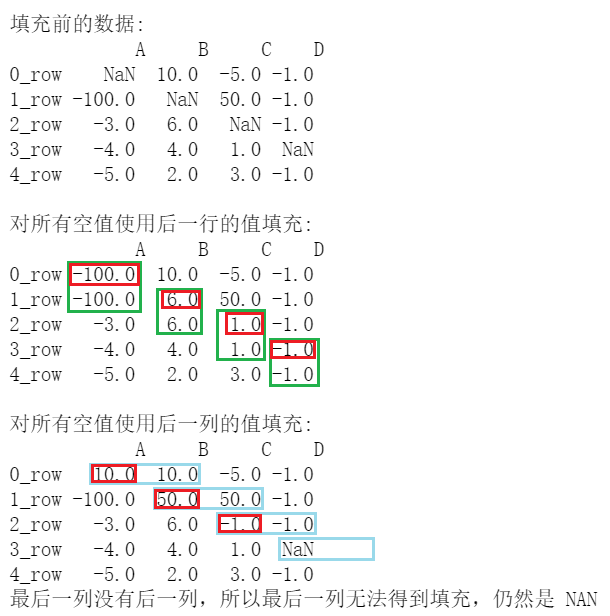
-
ffill 表示向前填充,即从前往后填充,inplace默认为False,即不修改原始数据
print('\n填充前的数据: \n', df2)
df6=df2.ffill()
print('\n对所有空值使用前一行的值填充: \n', df6)
print('第一行没有前一行,所以第一行无法得到填充,仍然是 NAN')
df7=df2.ffill(axis=1)
print('\n对所有空值使用前一列的值填充: \n', df7)
print('第一列没有前一列,所以第一列无法得到填充,仍然是 NAN')
-
interpolate 表示使用插值的方法来填充空值,inplace默认为False,即不修改原始数据。
print('\n填充前的数据: \n', df2)
df8=df2.interpolate()
print('\n对所有空值使用 前后行的数据进行差值计算 填充: \n', df8)
print('第一行没有前一行,所以无法计算插值,仍然是 NAN')
df9=df2.interpolate(axis=1)
print('\n对所有空值使用 前后列的数据进行差值计算 填充: \n', df9)
print('第一列没有前一列,所以无法计算插值 ,仍然是 NAN')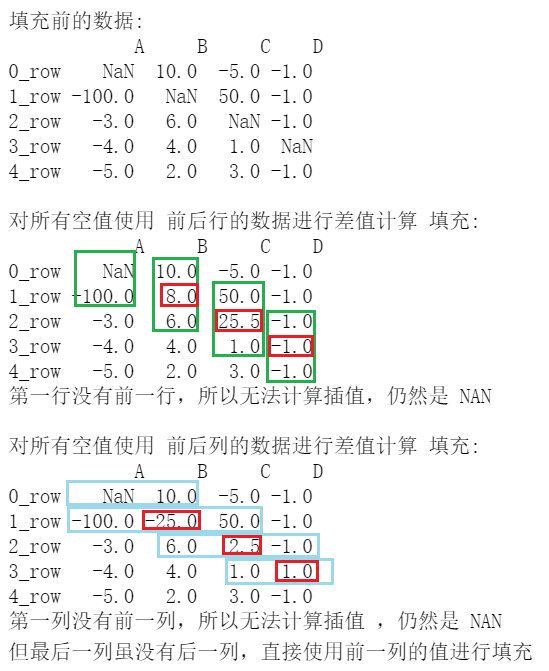
默认的差值方法为 method=’linear’,即线性插值,还可以使用其它多种插值方法,可以参考官方文档。
在使用插值时,建议设置 axis=1, 即用列数据进行插值,因为同一列是属于同一类数据的,而不同列之间往往是不同的数据(比如实际含义不同,或数据类型不同),所以不同列之间(行数据)插值往往不符合实际逻辑。当然如果数据情况允许,那么也可以用行数据进行插值。
至此,对于 DataFrame 对象的数据的简单操作就介绍完了,还有一些进阶操作,将在后面的篇章讲解。


