7-pandas数据分组聚合合并

7.pandas数据分组聚合合并
Pandas 处理数据时,常常会对数据分成若干个组,然后对各个组进行数据处理,比如求和、求平均值等,最后再将各个组的数据汇总起来形成一个新的数据集,这个过程通常被描述为“split-apply-combine” 。
所以本篇要讲的就是 Pandas 中涉及 分组、聚合、合并的一些操作。
在本章中依然使用 wine dataset 数据集:
import pandas as pd |
7.1 分组
7.1.1 groupby 方法
官方文档:groupby
groupby 函数是 Pandas 中分组的最核心函数,其基本参数如下:
by: 该参数用于确定groupby操作的分组依据,以是一个映射(mapping)、函数(function)、标签(label)、pd.Grouper对象或这样的对象的列表。- 如果
by是一个函数,那么这个函数会被应用到对象索引的每一个值上,依据函数的返回值进行分组; - 如果
by是 dict 或 Series,则将使用dict 或 Series 的值来确定分组; - …
- 如果
axis: 该参数用于确定 对数据沿着什么方向分组,默认为 0,即按行分组,为1时按列分组;该参数在未来新版本中可能会舍弃, 改为只对行数据进行分组,如果要对列数据进行分组,可以先将DataFrame进行转置;level: 该参数是DataFrame具备多层索引时才会用到,用于确定对多层索引的哪一层进行分组,默认为 None,即对所有层进行分组;也可以使用整数或索引名,或者由他们组成的元组序列;as_index: 该参数用于确定分组后,是否将分组的字段作为结果中的索引,默认为 True;- 当
as_index=True,groupby 操作后的返回结果会以分组标签作为索引,也就是说结果 DataFrame 的索引会是每个组的标签。这是最常见的使用方式。 - 当
as_index=False,groupby 操作后的返回结果会以原来的 DataFrame 的结构返回,也就是说结果 DataFrame 的索引和原 DataFrame 一样,而分组标签则成为新的列(或行)数据。
- 当
sort: 该参数用于确定分组后,是否对分组结果按照分组的键(依据)进行排序,默认为 True;但是不会影响分组内部数据的顺序。 如果将该参数设置为 False,一般会执行的快一点,特别是对于数据量很大的DataFrame;group_keys: 当调用apply并且by参数产生类似索引(即转换)结果时,向索引添加组键,以使得结果更具有可读性;observed: 该参数决定了对于分类组器(Categorical groupers)的处理方式,用于确定是否显示观察到的值,默认为 False,即显示观察到的值;当该参数设置为 True 时,会显示未观察到的值;不过该参数在2.1.0版本后被弃用;dropna: 该参数用于确定是否删除缺失的数据,默认为 False,即不删除缺失的数据;当该参数设置为 True 时,会删除缺失的数据;
7.1.2 GroupBy 对象
groupby() 函数并不是直接返回一个新的 DataFrame对象,而是返回一个 GroupBy 对象,该对象包含关于分组的信息。
DataFrame 应用 groupby() 之后,返回的是 pandas.api.typing.DataFrameGroupBy> 对象;
Series 应用 groupby() 之后,返回的是 pandas.api.typing.SeriesGroupBy 对象;
官方文档 : GroupBy
对于 GroupBy 对象,并不能直接查看其数据,如下所示:
# 依据 qual 列的值,对行数据进行分组 |

如果要查看 GroupBy 对象的信息,可以使用以下方法:
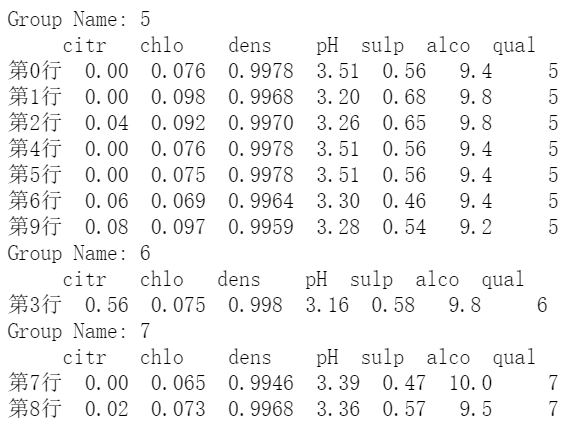
- 当作迭代器使用
# 会依次产出各个分组的 name 和 分组后的 DataFrame 子集 |
- groups 方法
会返回一个字典,字典的键为分组的组名,值为分组后聚在一起的标签:{group name : group labels}
# Dict {group name -> group labels}. |

- indices 方法
会返回一个字典,字典的键为分组的组名,值为分组后聚在一起的数据的序号:{group name : group indices}
# Dict {group name -> group indices}. |

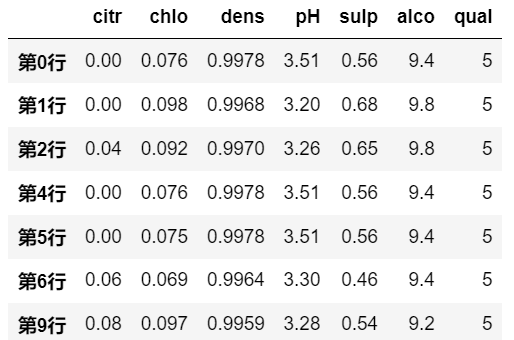
- get_group 方法
# 取 分组名为 5 的部分 |
7.1.3 分组示例
在知道如何查看 GroupBy 对象之后,可以来看一下 groupby() 方法的使用示例。
- 按标签分组示例
# 按标签分组示例, 令 by=列名 |
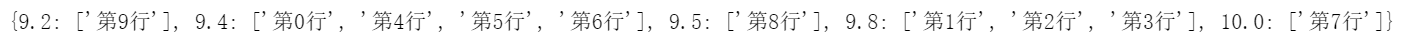
- 按函数分组示例
by 为函数时:it’s called on each value of the object’s index. 即将 DataFrame 对象的每个index都作为函数的输入去获取输出
# 按函数分组示例, 会将 DataFrame 的每个 index 作为函数的输入 |
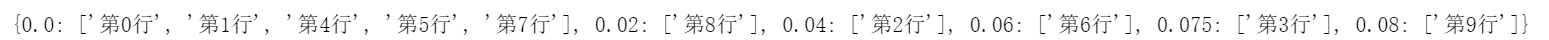
# 依据每一行 的 pH 的不同范围,映射不同的分组组名 |
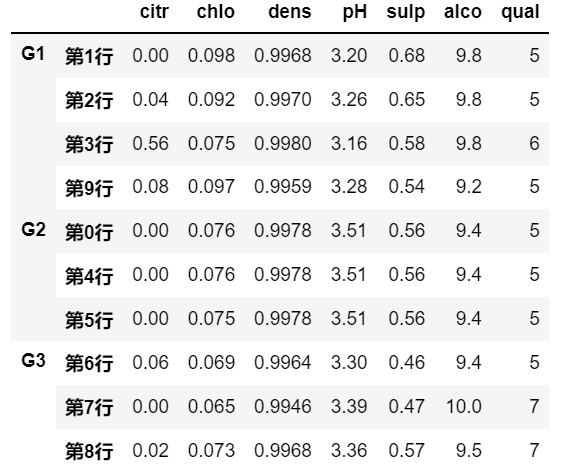
- 表达式分组示例
# by 为一个表达式,此例中的表达式是判断表达式, 所以会分为 False 或者 True 两种分组 |
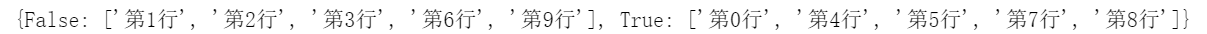
- as_index 示例
as_index 为 False 时,分组的组名不会作为index
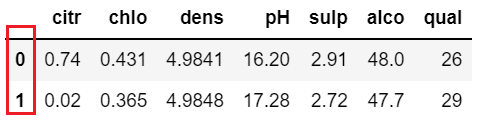
df.groupby(by=df.pH>3.3, as_index=True).sum() |
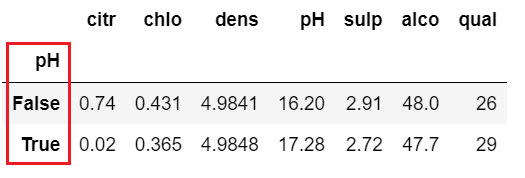
df.groupby(by=df.pH>3.3, as_index=False).sum() |
- 分组器 Grouper
分组器是 pandas 提供的一个可以执行较为复杂操作的分组工具,具体用法可以参考官方文档:Grouper
它在处理一些复杂结构的 DataFrame时比较高效,比如有时间序列的 DataFrame,这里不过多描述。
7.1.4 分组对象的操作
使用 groupby 方法对数据进行分组之后,可以对分组对象进行一些操作,来对各个分组的数据做进一步的处理。在 7.1.2 小节中介绍了查看分组对象的操作,这里主要是讲一下如何对分组数据进行处理的操作。
官方文档:function-application
apply
它和 DataFrame 的 apply 方法类似,只不过 DataFrameGroupBy 的 apply 方法是对分组后每个子集上的数据进行处理。从下面的code可以清晰的分辨出二者的区别:
# 使用 DataFrame 的 apply 方法, 默认情况下是对整个DataFrame的每列数据进行处理
# 所以下方的 code 是求每一列的均值
df.apply(lambda x:x.mean())
# 使用 groupby 对象的 apply 方法, 是对各个分组内的 DataFrame 进行处理
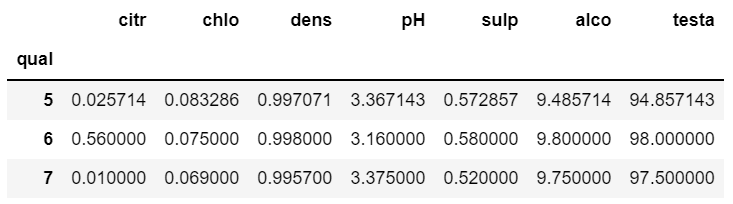
# 所以以下code是对 分组 5,6,7 的三个 子 DataFrame 进行处理,分别得到了 3个不同分组内 各列的数据的均值
df_groupby.apply(lambda x: x.mean() )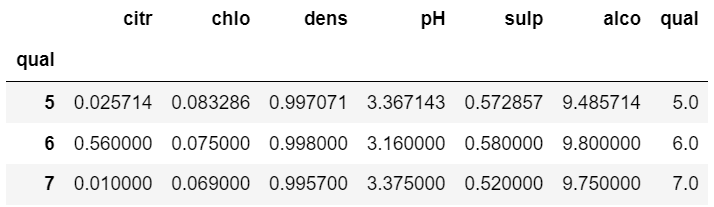
由于 apply 是一个非常灵活的方法,所以如果有一些特定的方法支持特定的操作,建议使用特定的操作,这样效率更高,比如上面两个code可以改写为:
df.mean()
df_groupby.mean()效果不变,但是运行效率更高。
# 定义一个 根据 col 的值,取最大的两行数据的函数
def first_2(sub_df_, col):
return sub_df_.nlargest(2, col)
# 对各个分组应用这个函数, 第一个 sub_df_ 已经由各个分组的子 DataFrame 自动传入了
df_groupby.apply(first_2, 'chlo')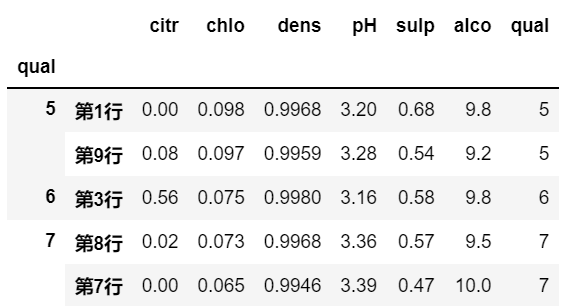
transform
它对每个分组调用一个函数,并返回一个与 原始 DataFrame 具有相同索引的 DataFrame,并使用经过转换的值替换原来位置的值。
官方文档:transform
# 依据 qual 分组, 然后对每组的数据应用 Transform
df.groupby(by='qual').transform('mean')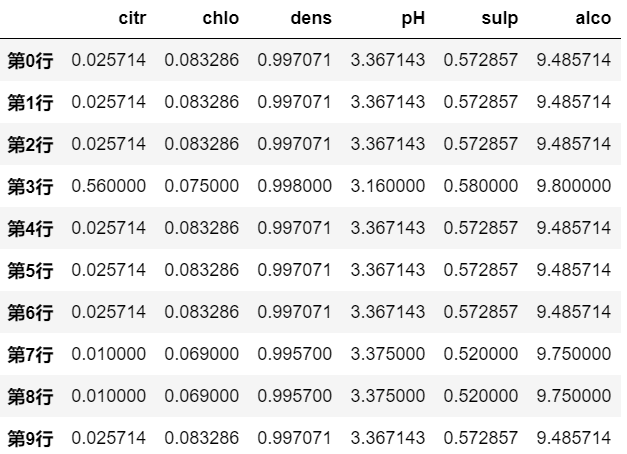
由示例结果可知,分组的组名并未被展示出来,且数据也并未按照组别进行分布,还是保持了与原来 DataFrame 的 index 相同的 index。 但是仔细观察的话,会发现, transform 确实是对各个组内的数据来进行应用的。
比如
- [‘第0行’, ‘第1行’, ‘第2行’, ‘第4行’, ‘第5行’, ‘第6行’, ‘第9行’] 的数据是一样的,这是因为这些行在分组时,被分到了同一个组(qual=5),
- [‘第7行’, ‘第8行’] 的数据是一样的,这是因为这两行在分组时被分到了(qual=7),
还剩一个[ ‘第3行’ ] 的数据独自成组(qual=6);
因此,各个组分别被应用了transform(‘mean’), 求出了各个组内的行均值,并且原始的行数据被该结果替换掉。
filter
它对每个分组调用判断标准,并返回一个布尔值,用于过滤分组,只保留通过过滤的组。
# 条件为: 各个分组内的 chlo列均值 小于 0.07
df.groupby(by='qual').filter(lambda x: x['chlo'].mean() < 0.07)
# 只会返回满足条件的组
# 其实可以应用 apply 函数来查看过滤条件返回的bool值
df.groupby(by='qual').apply(lambda x: x['chlo'].mean() < 0.07)
如果所示,filter 当中的过滤条件就是这样的,每个组都对应了一个 bool 值。
pipe
管道函数,可以将函数作为参数,将函数作用于分组后的数据。pipe 方法主要是为了增加可读性和代码简洁性。
# 增加新列的示例函数
def assign_new_col(df_, col):
df_['testa'] = df_[col]*10
return df_
# 用pipe管道对分组对象连续进行函数操作
df.groupby('qual').pipe(lambda x: x.mean()) \
.pipe(assign_new,'alco')