
6-pandas数据进阶操作

6.pandas数据进阶操作
6.1 按条件查询数据
在这里使用wine数据集作为示例:
import pandas as pd |
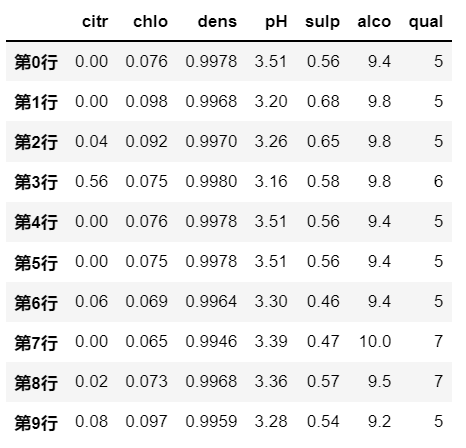
6.1.1 按逻辑筛选
之前在第5章介绍了数据的基础查询操作,比较常用的是 df['列名'], df.loc['索引标签'], df.iloc[序号] 这种形式去查询数据,在使用这些查询方式时,是支持按逻辑筛选的。
逻辑运算操作
针对索引的逻辑运算,返回的结果是一个array类型数组,该数组由布尔值组成,在符合条件的位置是 True, 不符合条件的位置是 False。
示例一
print('\n逻辑运算示例一:df.pH>3.3 \n ')
print(df.pH>3.3)
示例二
print("\n逻辑运算示例二:列数据逻辑判断,df.loc[:, 'pH']>3.3 \n")
print(df.loc[:, 'pH']>3.3)
示例三
print("\n逻辑运算示例三:行数据逻辑判断,df.loc['第2行']>0.9 \n")
print(df.loc['第2行']>0.9)
示例四
print("\n逻辑运算示例四:多个条件 and \n")
print((df['pH']>3.3) & (df['qual']==5))
示例五
print("\n逻辑运算示例五:返回的是一个二维 array \n")
print(df >0.5)
逻辑筛选操作
上面的逻辑运算操作返回的是一个布尔值数组,我们可以利用这个数组来筛选数据,返回的是筛选后的数据。
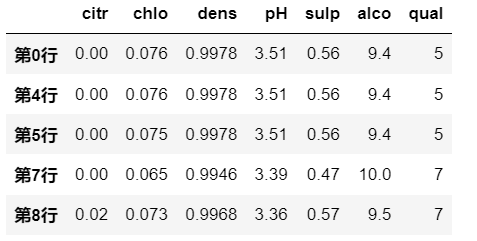
示例一:
逻辑运算
df.pH>3.3是对列数据做逻辑运算,
所以是在筛选哪些行满足条件df[df.pH>3.3]
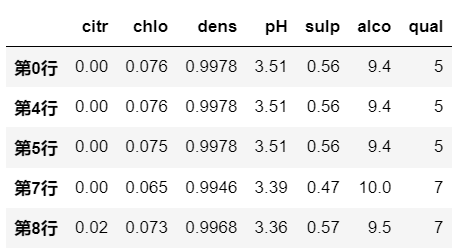
示例二:
逻辑
df.loc[:, 'pH']>3.3是对列数据做逻辑运算,
所以是在筛选哪些行满足条件df[df.loc[:, 'pH']>3.3]
示例三:
逻辑
df.loc['第2行']>0.9是对行数据做逻辑运算,
所以是在筛选一行当中哪些列满足条件df.loc[:, df.loc['第2行']>0.9]
示例四:
逻辑
df.loc[:, 'pH']>3.3和df.loc[:, 'qual']==5都是在操作列数据
所以是在筛选哪些行满足条件df[(df.loc[:, 'pH']>3.3) & (df.loc[:, 'qual']==5)]
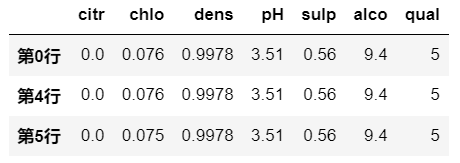
示例五:
逻辑运算是对 DataFrame 的所有元素进行计算
即 elementwise 的筛选
为True的位置会取,为False的位置是用NAN填充df[df >0.5]
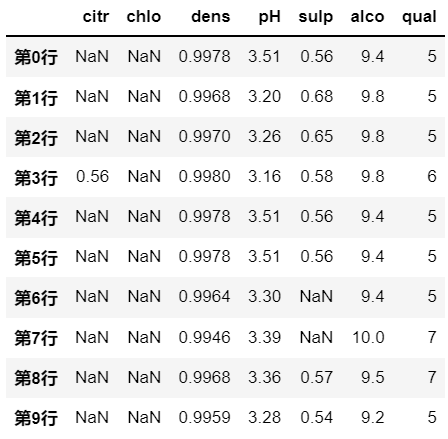
比较函数
在上面的逻辑运算中,用到的比较大小的符号,在pandas中有设置对应的函数:
| 函数 | 对应符号 | 含义 | 举例 |
|---|---|---|---|
| DataFrame.lt() | < |
小于 | df['pH'].lt(3.3) |
| DataFrame.le() | <= |
小于等于 | df['pH'].le(3.3) |
| DataFrame.gt() | > |
大于 | df.gt(1.1) |
| DataFrame.ge() | >= |
大于等于 | df.ge(1.1) |
| DataFrame.eq() | == |
等于 | df.eq(5.5) |
| DataFrame.ne() | != |
不等于 | df.ne(3.3) |
| DataFrame.isin() | in |
是否在 | df['pH'].isin([3.3]) |
6.1.2 query() 条件查询
query() 函数可以对 DataFrame 进行条件查询, 返回的是筛选后的 DataFrame。
官方文档:query
示例一
df.query('sulp > 0.55') # 相当于 df[df.sulp > 0.55]
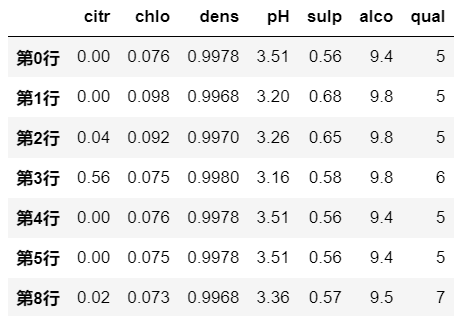
示例二
df.query('pH > alco/3') # 相当于 df[df['pH']>df['alco']/3]
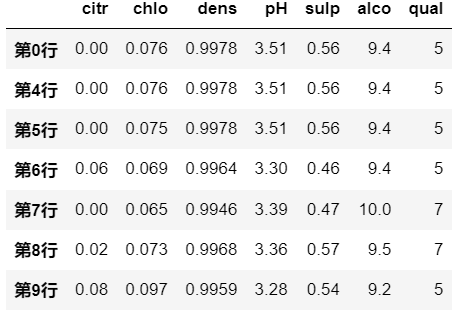
6.1.3 filter()
filter 根据指定的索引标签(行名or列名)筛选出 DataFrame的子集。
官方文档:filter
可接收参数有:
items:list格式的列名or行名;like: 字符串,模糊查询;regex: 正则表达式,模糊查询;axis: 0 表示行,1表示列;示例一
# axis = 0 ,筛选满足条件的 行
df.filter(items=['第0行','第9行' ], axis=0)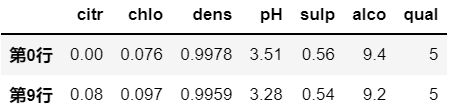
示例二
# axis = 1 ,筛选满足条件的 列
df.filter(items=['citr','pH' ], axis=1)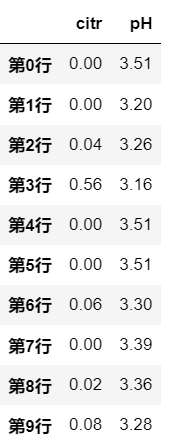
示例三
# 使用模糊查询,筛选出列名中含有 s 的列
df.filter(like='s', axis=1)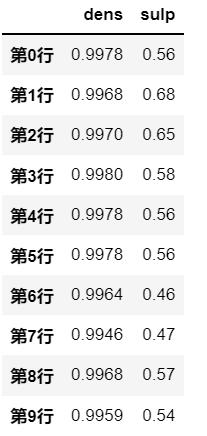
示例四
# 使用正则表达式模糊查询, 筛选出列名以 o结尾 的列
df.filter(regex='o$', axis=1)
6.2 查看统计信息
6.2.1 描述统计信息
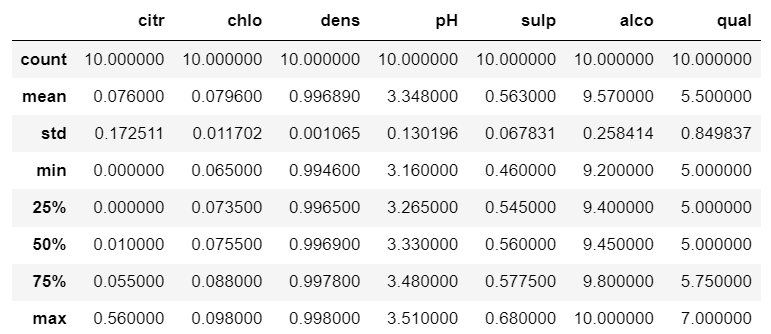
describe()
官方文档: describe()
describe是返回一个总结性的统计信息描述。可接收参数有:percentiles:返回分位数的参数,默认为 25%, 50%, 75%;include:返回统计信息的列,默认为所有列;exclude:排除的列,默认为空;
会返回 DataFrame 或者 Series 的 列数据的 数目、平均值、标准差、最小值、最大值、分位数(默认为 25%, 50%, 75%分位)
df.describe()
6.2.2 统计函数
DataFrame 本身还有一些数学统计函数,用来获取特定的统计信息。
这些统计函数包含mean、median、std、var、min、max、sum、quantile等。大部分都有 axis 这个参数,表示统计数据的考察范围是行还是列。
- axis 默认为0,表示将 DataFrame 看作行数据
- axis 设置为1,表示将 DataFrame 看作列数据
| 方法 | 描述 |
|---|---|
| mean() | 平均值 |
| median() | 中位数 |
| std() | 标准差 |
| var() | 方差 |
| min() | 最小值 |
| max() | 最大值 |
| mode() | 众数 |
| quantile() | 分位数 |
| corr() | 相关系数 |
| cov() | 协方差 |
| kurt() | 峰度 |
| skew() | 偏度 |
这里展示一些值得讲的方法的示例:
mode()
官方文档: mode()
这个是取众数,但是众数有可能不止一个值,比如一列数据中有两个数出现的次数都是最高,所以就是有两个众数,那么这个方法会返回两个众数,比如:
df.mode()
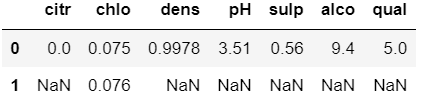
其中有两行数据的列,就是有两个众数;第二行中为NAN的列,就说明其只有一个众数,在第一行就已经显示了。
quantile()
官方文档: quantile()
用来计算分位数,其可接收参数为:
q:分位数,默认为0.5,表示中位数;
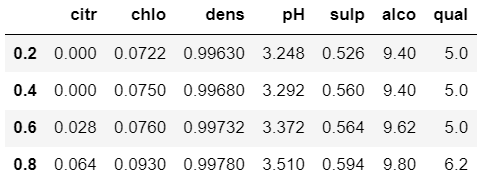
也可以接收一个数组,表示计算多个分位数,比如[0.25,0.5,0.75]表示计算三个分位数。interpolation:计算分位数的插值方式,默认为linear,表示线性插值,还有nearest、lower、higher和midpoint的方式,各自代表的意思可以查看官方文档。- method:考虑数据的范围,默认为’single’,即考虑各个列的数据;还可以选择’table’,即考虑整张 DataFrame 表的数据。
df.quantile([0.2, 0.4, 0.6, 0.8])
corr()
官方文档: corr()
计算列数据之间两两相关系数,但不会包括NA/null值;其可接收参数为:
method:计算相关系数的类型,默认为’pearson’,还可以选择’kendall’和’spearman’;min_periods:表示最小样本数,默认为1,表示计算相关系数时,如果某列数据少于1个,则不参与计算;numeric_only: 表示是否只计算数值类型数据(Include only float, int or boolean data),默认为False,计算所有数据。
df.corr()
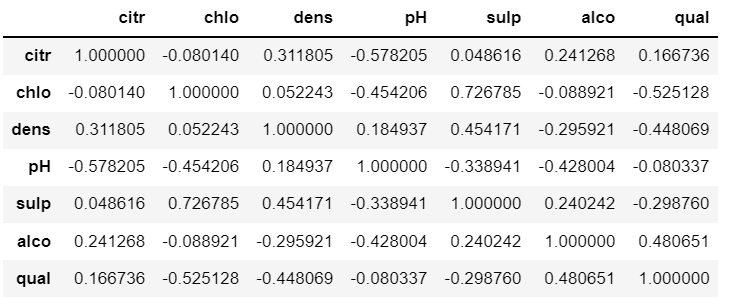
返回的 DataFrame 对象其实就是相关矩阵,其中对角线上的元素为1,表示各列与自身的相关系数。其他位置的值,表示两两列之间的相关系数。
很明显这是一个对称矩阵,即真正有用的信息只有一半。
cov()
官方文档: cov()
计算列数据之间的协方差,但不会包括NA/null值;其可接收参数为:
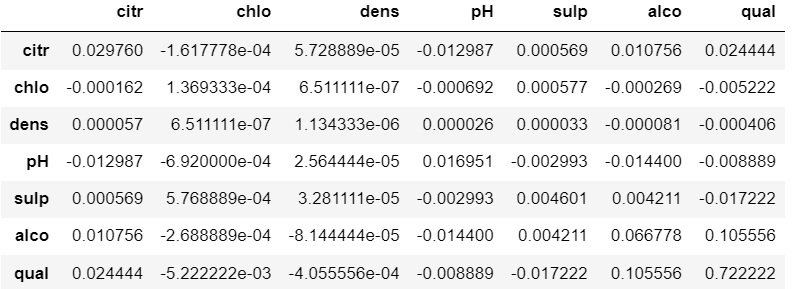
min_periods:表示最小样本数,默认为1,表示计算协方差时,如果某列数据少于1个,则不参与计算;ddof:自由度。在计算中使用的除数是N - ddof,其中N表示元素的数量。此参数仅在数据框中没有nan时才适用。numeric_only: 表示是否只计算数值类型数据(Include only float, int or boolean data),默认为False,计算所有数据.
df.cov()
kurt()
官方文档: kurt()
在新版pandas中,建议使用 kurtosis()。
是用来计算列数据的峰度值。axis默认为0,及考虑列数据。
df.kurt() # 新版建议使用 df.kurtosis()

skew()
官方文档: skew()
是用来计算列数据的偏度系数(均值偏离中位数的程度)。
df.skew()

6.3 数据排序
6.3.1 按索引排序-sort_index
官方文档:sort_index()
sort_index 按照 行索引 或者 列索引来进行排序。 默认不修改原数据,返回的是排序后的新 DataFrame,可以更改 inplace 参数。
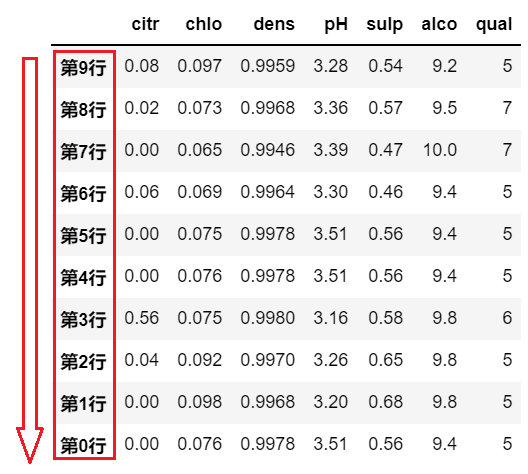
# 按照行索引,降序排列 |
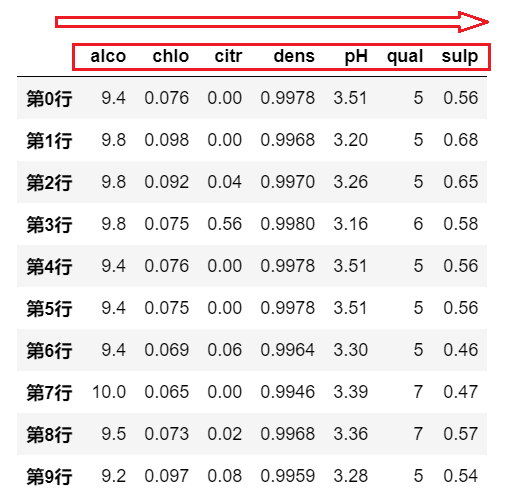
# 按照列索引,升序排列 |
6.3.2 按数据值排序-sort_values
官方文档:sort_values()
sort_values 按照数据值进行排序,通过传入的 by 参数来作为排序的依据。 默认不修改原数据,返回的是排序后的新 DataFrame,可以更改 inplace 参数。
示例一:
# by=列名,axis=0,表示依据某列的数据值,对各行进行排序
df.sort_values(by='alco', axis=0, ascending=True)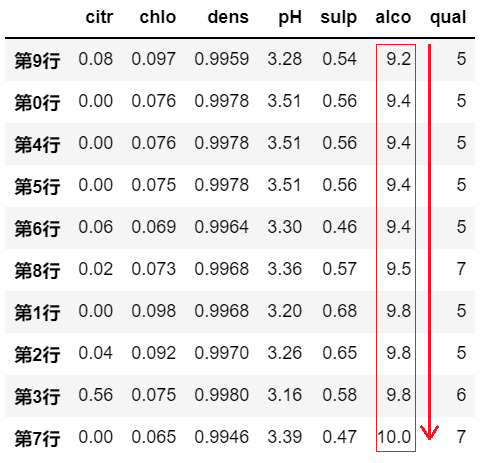
示例二:
# by=行名,axis=1,表示依据某行的数据值,对各列进行排序
df.sort_values(by='第0行', axis=1, ascending=True)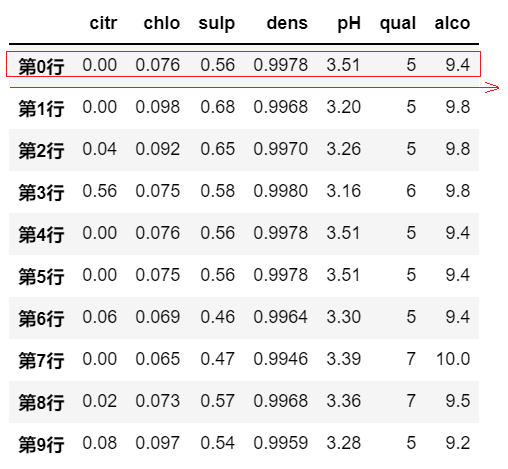
示例三:
# by=[列名1, 列名2, ..],axis=0,
# 表示依据多列的数据值,对各行进行排序;
# 多列数据的优先级依照list中的顺序考虑
df.sort_values(by=[ 'qual','pH'], axis=0, ascending=True)
# 这个意思是优先考虑 qual 的数据值,当某两行数据的 qual 也相同时,再对比它们 pH 的数据值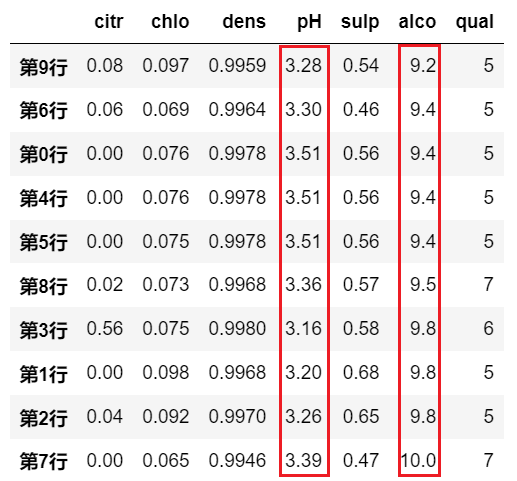
示例四:
# by=[行名1, 行名2, ...] ,axis=1,
# 表示依据多行的数据值,对各列进行排序
# 多行数据的优先级依照list中的顺序考虑
df.sort_values(by=['第0行', '第1行'], axis=1, ascending=True)
# 这个意思是优先考虑 第0行 的数据值,当某两列数据的 第0行 也相同时,再对比它们 第1行 的数据值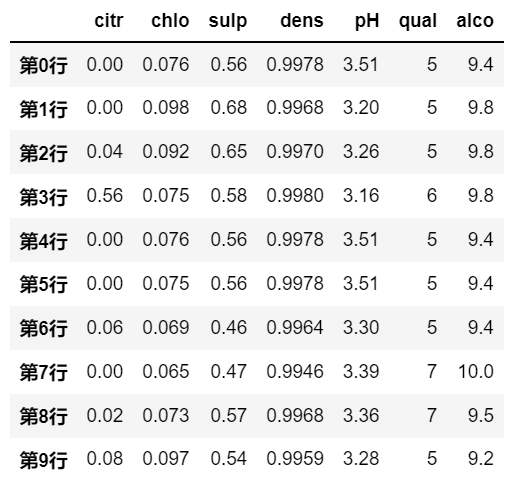
6.3.3 混合排序
sort_values 这里的 values 其实也能是 index 的 values,即 sort_values 也能实现 sort_index 的功能;
比如给行索引命名后,就能取到行索引的值,然后对行索引进行排序:
# 先给index命名, 为了避免修改原始数据,这里将新 DataFrame 赋值给df2 |
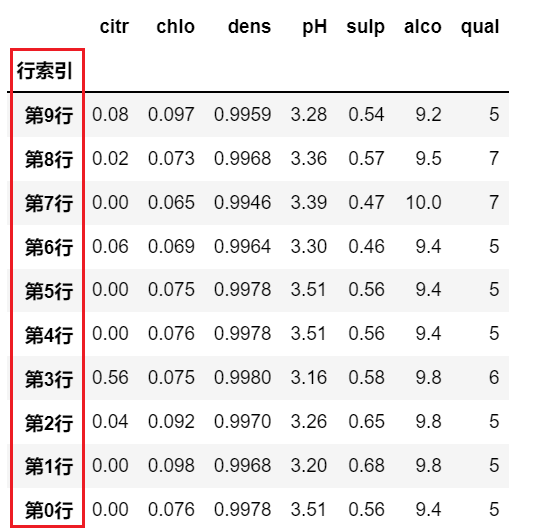
所以,既然 sort_values 也能实现 sort_index 的功能,那么 就能同时使用 index 的值 和数据列的值进行混合排序:
# 利用该该特性,实现混合排序,优先考虑 alco 列的数据,其次考虑行索引值 |
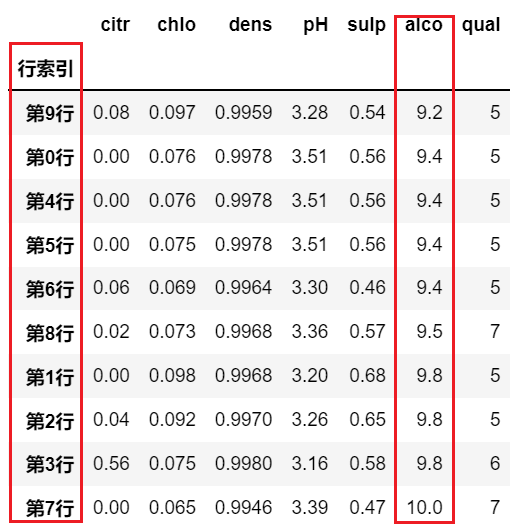
6.3.4 取最大/最小的topN数据
nsmallest
官方文档:nsmallest
返回数据列中前n个最小值的数据行;可接收参数:
- n : 返回n行数据;
- columns: 列名或者列名组成的list,表示排序的依据;
keep:first、 last、all, 表示遇到重复数据时取哪一个,默认为all,全取(所以可能会返回超过n行)。
df.nsmallest(2,'qual')
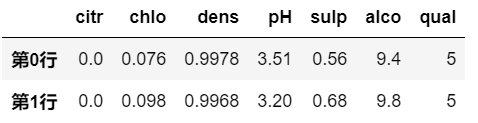
nlargest
官方文档:nlargest
返回数据列中前n个最大值的数据行;可接收参数:
- n : 同上;
- columns: 同上
keep:同上
df.nlargest(2,'alco')
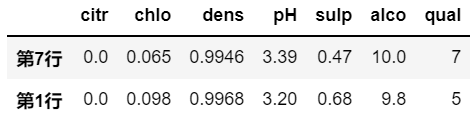
对于 df.nsmallest(n, column),其操作相当于 df.sort_values(columns, ascending=True).head(n);
对于 df.nlargest(n, column),其操作相当于 df.sort_values(columns, ascending=False).head(n);
但是使用 nsmallest 和 nlargest 函数,效率更高;
在python的优先队列 heapq 模块中,也提供了 nsmallest 和 nlargest 这两个函数,它们内部的原理是使用堆排序,而且不用对所有数据进行排序,时间复杂度应该是 O(klogN),其中 k 是取的topk的值。我估计pandas这两个函数也是采用的类似的方法,所以效率会更高。
6.4 数据掩膜
6.4.1 where
官方文档:where
给予一个判断条件,where 对 DataFrame 中不满足条件的地方进行处理,一般是替换为某值,该值可以由用户输入,默认使用NaN。
主要参数简介:
cond: 布尔类型,表示判断条件;other: 表示不满足条件的位置用什么值进行替代,默认为NaN;inplace: 表示是否修改原数据,默认为False;axis: 表示对行还是对列进行操作,默认为0,表示对行进行操作;level: 表示对多层索引进行操作,默认为None,表示对所有索引进行操作;
示例一:
# 不满足条件的地方默认为 NaN
df.where(df>0)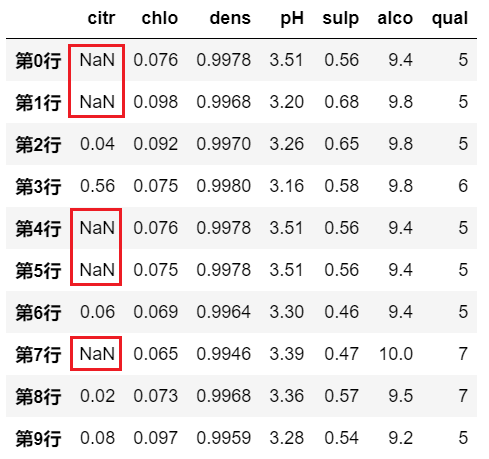
示例二:
# 可以用自己指定的值来填充不满足条件的位置
df.where(df>0,'不满足条件的位置')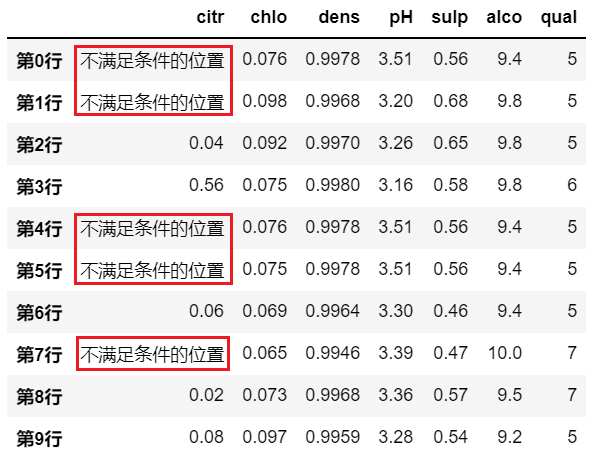
示例三:
判断条件不一定非得是对于整个DataFrame的element-wise的条件
也可以用之前提到的 关于 行或者列 的逻辑运算条件
比如下例就是使用 pH 值是否大于3.3来对行数据进行操作df.where(df.pH>3.3)
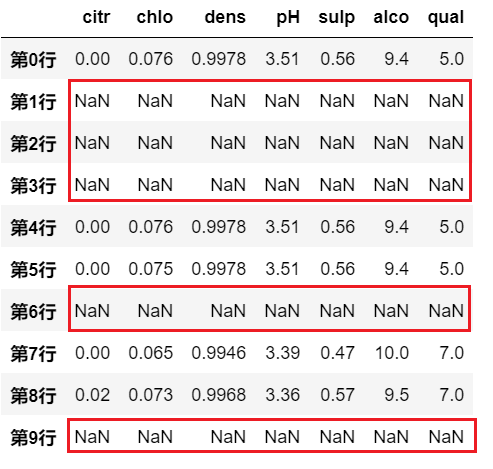
示例四:
#同样对不满足条件的行/或者列可以用指定值填充
df.where(df.pH>3.3, '99999')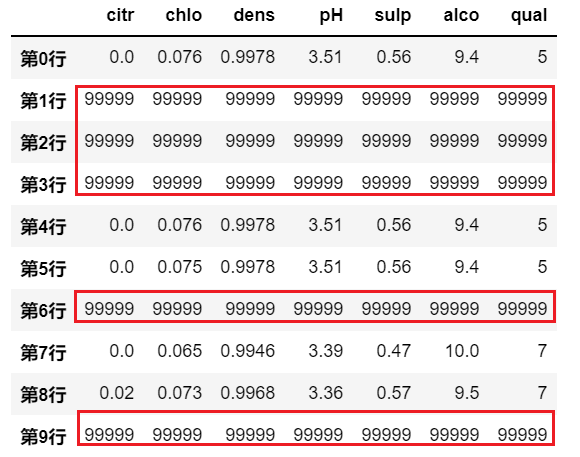
示例五:
上面的例子都是使用一个标量(比如字符串/一个数值)来进行替换,实际上,并不局限于使用标量,也可以使用 Series 或者 DataFrame 来进行替换:
# 用于填充的值不一定非得是一个标量,也可以是一个Series/DataFrame
df.where(df.pH>3.3, pd.Series({'citr':-1, 'chlo':-2, 'dens':-3, 'pH':-4, 'sulp':-5, 'alco':-6, 'qual':-7}), axis=1)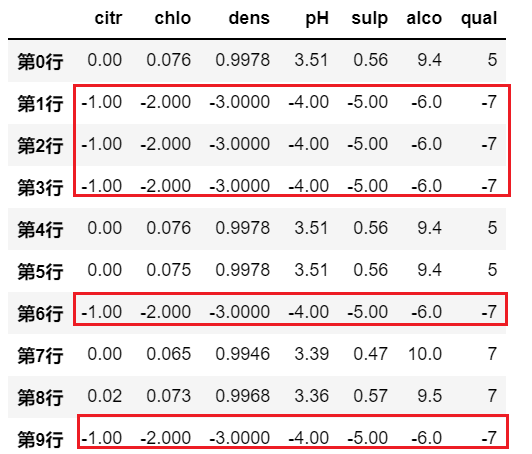
6.4.2 mask
官方文档:mask
mask 操作与 where 操作是对偶操作,只不过 where 是对不满足条件的地方填充,而 mask 是对 满足条件的地方进行填充。
示例一:
# 满足条件的地方默认为 NaN
df.mask(df>0)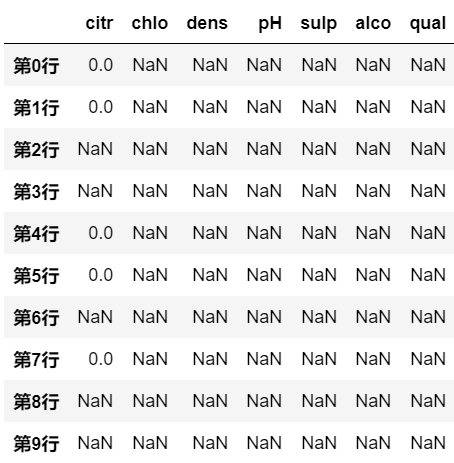
示例二:
# 可以用自己指定的值来填充 满足条件 的位置
df.mask(df>0,'满足条件')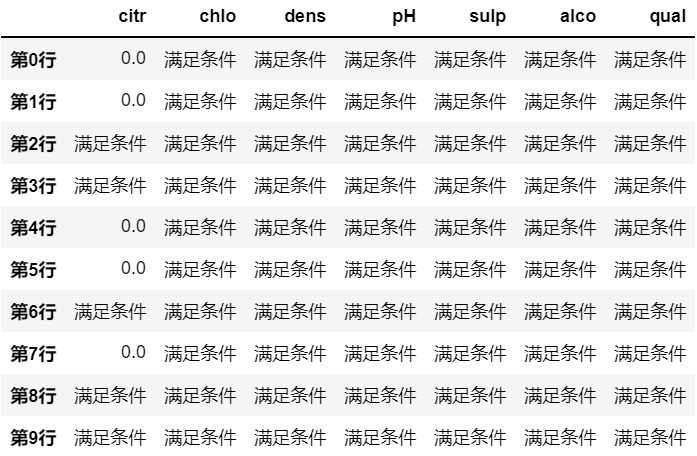
示例三:
# 满足条件的行数据被遮掩
df.mask(df.pH>3.3)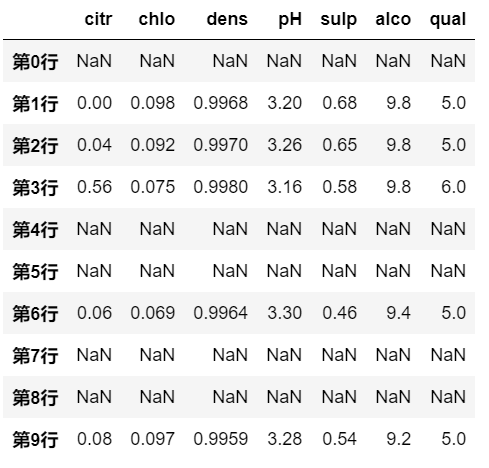
示例四:
# 满足条件的行数据被填充替换
df.mask(df.pH>3.3, '99999')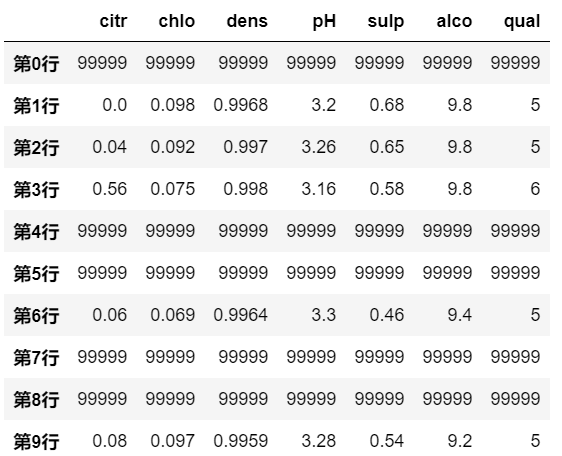
示例五:
# 满足条件的行数据被填充替换
df.mask(df.pH>3.3, pd.Series({'citr':-1, 'chlo':-2, 'dens':-3, 'pH':-4, 'sulp':-5, 'alco':-6, 'qual':-7}), axis=1)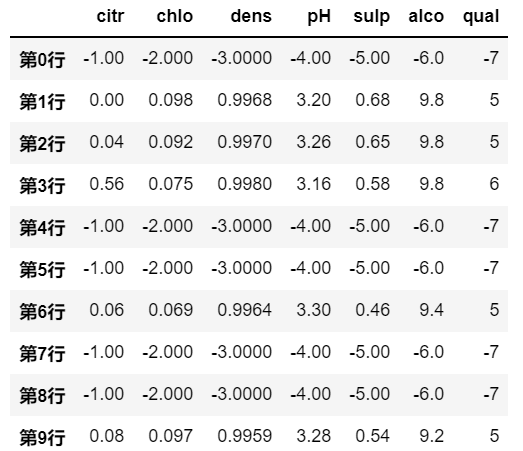
6.5 数据转换
astype
官方文档:astype
这是最常用、最简便的一种转换数据类型方法;
查看 DataFrame 的数据类型:print(f'当前 DataFrame 的数据类型为:\n{df.dtypes}')

同时转换所有元素的数据类型:
# 因为不会修改原始数据,所以将修改后的DataFrame赋值给一个新的df2
df2 = df.astype('float32')
print(f'当前 DataFrame 的数据类型为:\n{df2.dtypes}')
根据不同的列名,指定不同的类型:
df2 = df2.astype({'qual':'int32', 'pH':'float64'})
print(f'当前 DataFrame 的数据类型为:\n{df2.dtypes}')
也可以对某一列Series转换类型:
# 对单个列数据修改类型的方法
df2['chlo'] = df2['chlo'].astype('str')
print(df2.dtypes)
6.6 产生数据迭代器
6.6.1 使用zip对列数据进行打包
# 将列 pH 和 alco 的数据进行打包 |

6.6.2. iterrows()
将 DataFrame 的行数据 转换为产出 (index, Series) 的迭代器。
官方文档:iterrows
#使用 iterrows 生成行数据的迭代器 |
6.6.3. itertuples()
将 DataFrame 的行数据 转换为产出带名字的元组的迭代器。元组的名字默认使用’Pandas’。
df.itertuples()的运行效率比df.iterrows()高,因此,在处理大型DataFrame时,推荐使用df.itertuples()方法来迭代数据,因为它可以提供更高的运行效率和更少的内存占用。
官方文档:itertuples
for row in df.itertuples(): |

6.6.4. items()
将 DataFrame 的列数据 转换为产出 (列名, Series) 的迭代器。
注意:在老版本的pandas中可能使用的是 iteritems , 但该方法在新版本中已经被弃用。
官方文档:items
for col_name, col_data in df.items(): |
6.7 使用函数处理
在对 DataFrame 的数据进行处理时,有时候其自带的方法可能无法完全满足需求,所以可以对 DataFrame 应用一些更为复杂的函数操作进行处理。
6.7.1 apply()
官方文档:apply
对DataFrame按行或者列进行函数处理;其主要参数为:
func:函数,函数的参数为DataFrame的行(或者列),返回值为Series或者DataFrame;axis:默认为0,表示对列数据进行处理;1对行数据进行处理;raw:决定行(或列)作为 Series 或者是 narray 对象传递;默认为 False,表示传递为 Series 对象;True表示传递为 narray 对象;result_type:该参数仅仅当axis=1(处理行数据)时发挥作用,默认为None,取决于应用函数的返回值:类似列表的结果将作为一个Series返回。但是,如果apply函数返回一个Series,则将它们展开为列。;expand:如果结果为列表形式,它将被转换为列;reduce: 如果可能的话,返回一个Series而不是扩展列表结果。这是’expand’的反面;broadcast: 结果将被广播为原始的DataFrame形状,原始的索引和列将被保留。
args:表示函数的参数;by_row: 只有当func是一个类似列表或字典的函数集合,并且单个函数不是一个字符串时,by_row参数才会起作用。- 如果by_row设置为”compat”,Pandas会尝试将提供的函数转换为一个对应的Pandas方法(例如,Series().apply(np.sum)会被转换为Series().sum())。如果这种转换成功,函数将被应用到DataFrame或Series的每一行。如果转换失败,Pandas会尝试再次调用apply()函数,这次将by_row设置为True。如果这仍然失败,Pandas会再次调用apply()函数,这次将by_row设置为False,这是向后兼容的设置。
- 如果by_row设置为False,那么提供的函数将被一次性应用到整个DataFrame或Series。
- 简单来说,当by_row=’compat’时,Pandas会尝试逐行应用函数,如果逐行应用失败,则会尝试一次性应用。如果by_row=False,则函数会被一次性应用到整个DataFrame或Series。
示例一:
# 对行数据 应用 max 函数 |
示例二:
# 对行数据 使用 lambda 匿名函数 |
示例三:
result_type=’expand’ 举例,直接在示例二的code的基础上增加 参数 result_type='expand'
# 处理行数据, 且返回的是list,调用 result_type='expand',则结果会被转换为列 |
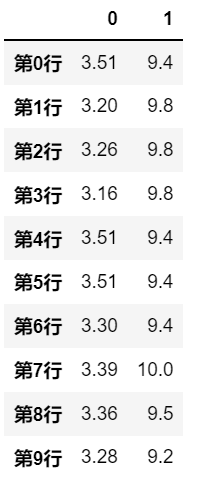
示例四:
result_type=’reduce’ 举例,直接在示例二的code的基础上增加 参数 result_type='reduce'# 对列数据进行处理
# 取每一列 第1至第4号元素
df.apply(lambda col: col[1:5], axis=0)

会发现与示例2的结果一样,因为reduce本身就是希望最后能尽可能的返回一个 Series,而默认 的 None 参数本来就是希望对于返回的 list 结果能作为 Series返回。
示例五:
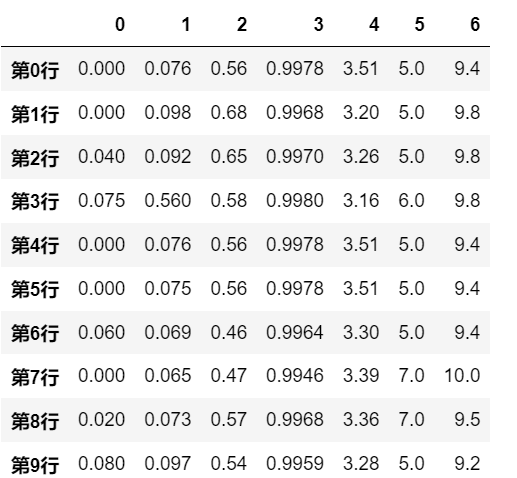
观察 result_type=’expand’,和 result_type=’broadcast’ 的区别
# 本来对row的处理是返回结果为list, 但使用 result_type='expand' 后会将其扩展为列 |
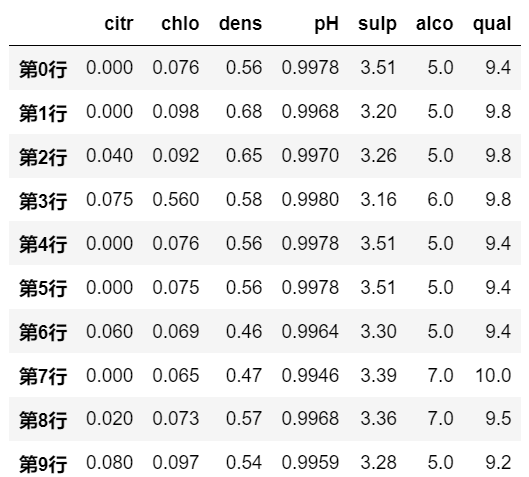
# result_type='broadcast'是将结果扩展为原来的DataFrame的形状; column 的名称是保留了原来的顺序, |
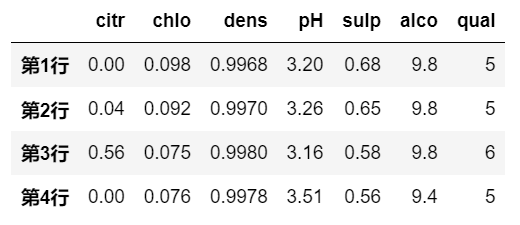
示例六:
# 对列数据进行处理 |
6.7.2 applymap()
官方文档:applymap
从 版本2.1.0开始, DataFrame.applymap 就已经被弃用. 改为使用 DataFrame.map.
6.7.3 map()
官方文档:map
将一个函数应用到DataFrame的每一个元素上,这个函数接受一个标量(scalar)并返回一个标量。
# 将每个元素都转换为字符串格式,并且求其长度 |
6.7.4 transform()
官方文档:transform
DataFrame或Series自身调用函数并返回一个与自身长度相同的数据。
它和 apply 很类似,但是也有不同,即apply 是对整个 DataFrame 或者 Series 进行操作,也就是它可以实现跨行或者跨列的操作,但是 transform 只能对一个对象进行操作,也就是只能实现单行或者单列的操作。
另外,transform 更多的是用于聚合操作时,对于组内数据进行处理;这一点在后面讲聚合操作时会讲到。
6.7.6 copy()
官方文档:copy
当希望用到 深拷贝 时,可以使用 copy() 方法。这一点可以联系 python 当中的 深拷贝和浅拷贝进行理解。
参数 deep 为 True 的时候,就是进行深拷贝-deepcopy;
参数 deep 为 False 的时候,就是进行浅拷贝-shallowcopy。


