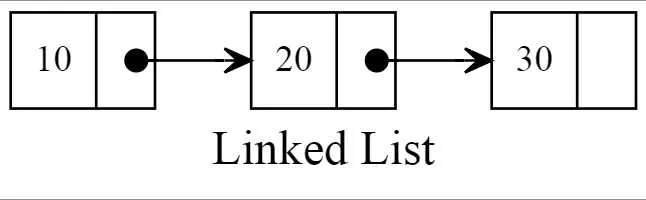
defappend(self, val) -> bool: '''尾插法''' node, cur = Node(val), self.__head # 这里就需要先判断是否为空,否则None.next会报错 if cur isNone: self.__head = node returnTrue else: # 循环结束后,cur指向最后一个数据结点 while cur.nextisnotNone: cur = cur.next cur.next = node returnTrue
definsert(self, pos, val) -> bool: '''随机位置插入''' # 先确保传入的pos属于[0, size] if pos < 0or pos > self.size(): print("insert pos out of range!") returnFalse else: if pos == 0: return self.add(val) else: node = Node(val) i, cur = 0, self.__head # 循环结束后, cur指向pos-1的位置,因为pos的位置要留给node while cur.nextisnotNoneand i < pos-1: cur = cur.next i += 1 # print('i:',i,end='->') # print(cur.val) node.next = cur.next cur.next = node returnTrue
############### 【删】############### defremove(self, val) -> bool: '''根据值来删除第一个符合条件的结点''' if self.is_empty(): print("the linklist is empty!") returnFalse
pre, cur = None, self.__head while cur isnotNone: if cur.val == val: # 先要判断是否删除的是首结点 if cur == self.__head: # 更新首结点 self.__head = self.__head.next cur = self.__head returnTrue else: pre.next = cur.next cur = pre.next returnTrue else: pre = cur cur = cur.next returnFalse
defdel_pos(self, pos) -> bool: '''根据位置来指定删除''' if pos < 0or pos > self.size()-1: print("del pos out of range!") if self.is_empty(): print('the linklist is empty!') returnFalse else: # 先要判断是否删除的是首结点 if pos == 0: # 更新首结点 self.__head = self.__head.next returnTrue else: i = 0 pre, cur = None, self.__head # 循环结束后, cur指向pos的位置 while cur.nextisnotNoneand i < pos: pre = cur cur = cur.next i += 1 pre.next = cur.next returnTrue
############### 【改】############### defchange(self, pos: int, val) -> bool: '''根据位置改变值''' if pos < 0or pos > self.size()-1: print("change pos out of range!") if self.is_empty(): print('the linklist is empty!') returnFalse else: i, cur = 0, self.__head # 循环结束后, cur指向pos的位置 while cur.nextisnotNoneand i < pos: i += 1 cur = cur.next cur.val = val returnTrue
############### 【查】############### deffind(self, val): '''依据值来定位位置(索引)''' i, cur = 0, self.__head while cur isnotNone: if cur.val == val: return i else: i += 1 cur = cur.next print('not find %s' % str(val)) returnFalse
deflocate(self, pos: int): '''依据索引查找值''' if pos < 0or pos > self.size()-1: print("out of range!") if self.is_empty(): print('the linklist is empty!') returnFalse else: i, cur = 0, self.__head # 循环结束后, cur指向pos的位置 while cur.nextisnotNoneand i < pos: i += 1 cur = cur.next return cur.val
6.1.1.3 带头结点单链表的实现
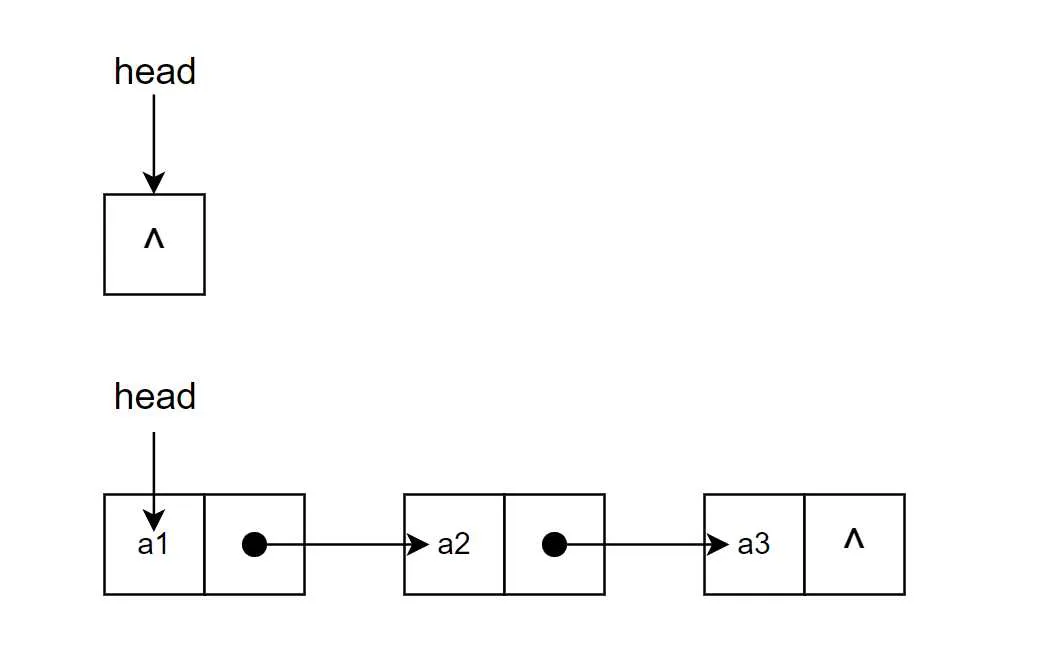
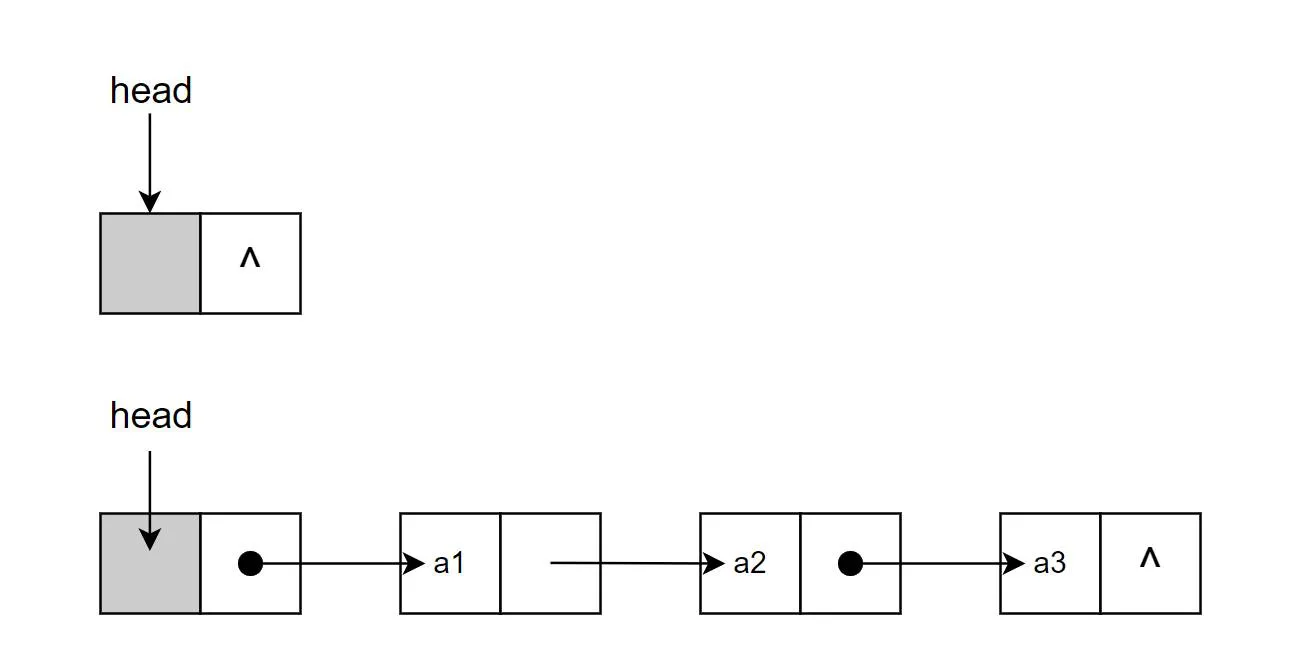
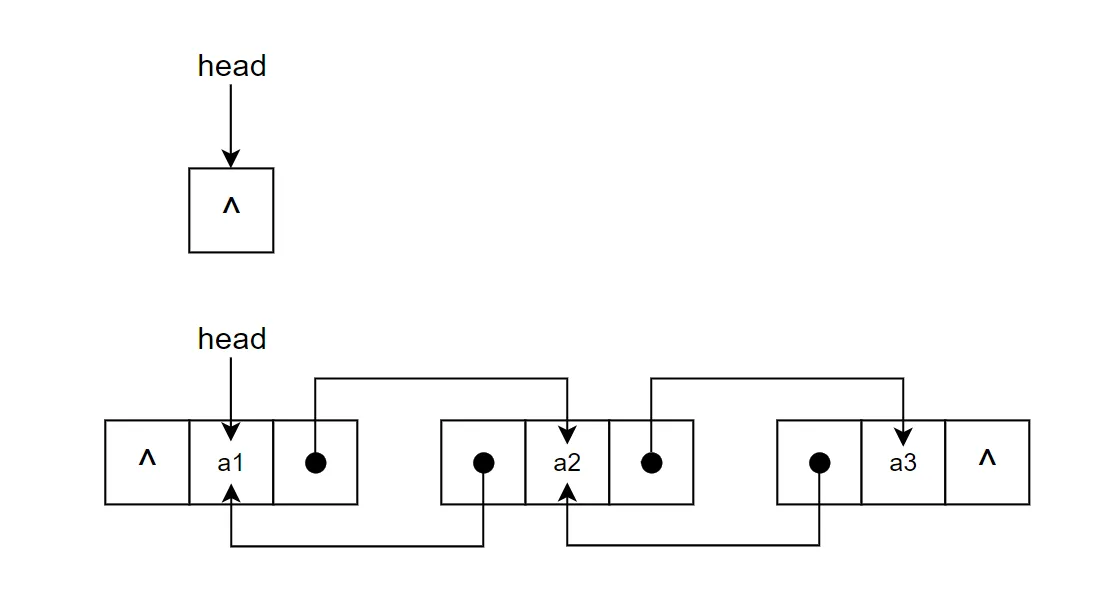
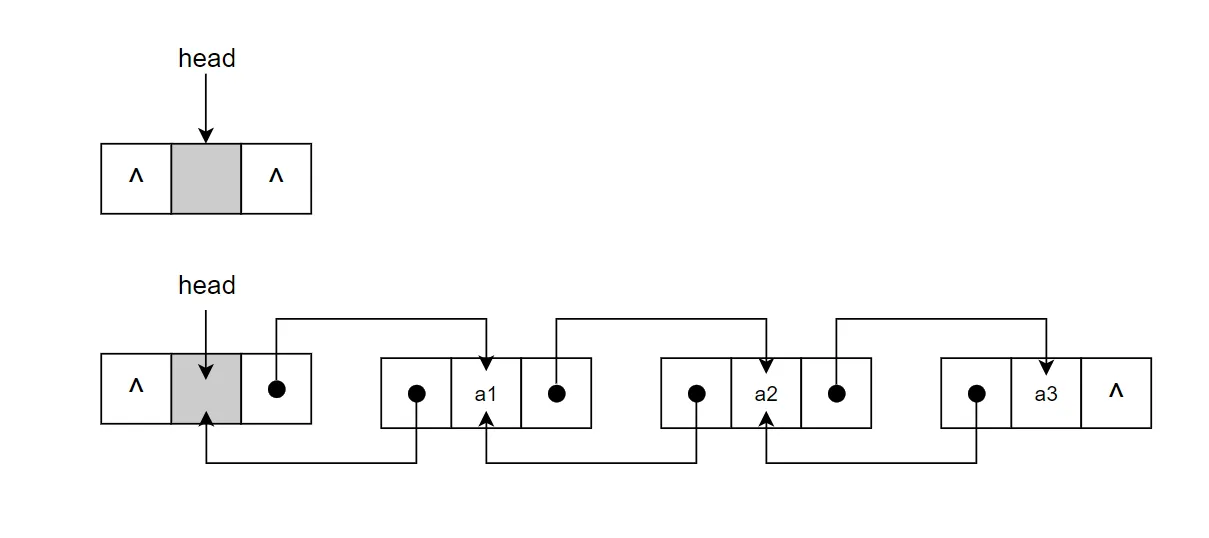
带头结点的单链表逻辑思考上更为简单一点,其与【不带头结点】的链表的核心差别主要有以下:
head 一定不为空,在首结点进行操作时,与其他位置的操作是一致的;
当游标cur 指向 head 时,其索引为 -1,表示首结点的前一位置,即首结点是从 head.next 开始算起。
掌握好这两个关键点,实现起来就十分简单了.
classSingle_Link_List_With_Head(object): def__init__(self, node=None): """ 这里实现的是所谓【带头结点】的单链表 所以初始化时不是为None或者从外面传入的node 初始化时就一定是一个结点,我们可以用这个结点的数据域来存储链表的长度 """ self.__head = Node(0) self.__head.next = node defis_empty(self)->bool: return self.__head.nextisNone defsize(self)->int: cnt, cur = 0, self.__head while cur.nextisnotNone: cnt +=1 cur = cur.next # self.__head.val = cnt # 也可以用头结点的数据域来存储链表长度 return cnt deftravel(self): cur = self.__head while cur.nextisnotNone: cur = cur.next print(cur.val, end='->') print('None') ###############【增】############### defadd(self, val)->bool: node = Node(val) # 注意这一步和不带头结点的链表的区别 node.next = self.__head.next self.__head.next = node returnTrue defappend(self, val)->bool: node= Node(val) cur = self.__head # 这里就不用单独判断链表是否为空了 # 空链表也包含在下面的情况 while cur.nextisnotNone: cur = cur.next cur.next = node returnTrue definsert(self, pos:int, val)->bool: if pos < 0or pos > self.size(): print('failed! insert pos out of range!') if self.__head.nextisNone: print('empty link-list!') returnFalse else: node = Node(val) i, cur = -1, self.__head while cur.nextisnotNoneand i<pos-1: cur = cur.next i+=1 node.next = cur.next cur.next = node returnTrue ###############【删】############### defremove(self, val)->bool: if self.is_empty(): print('empty link-list!') returnFalse pre, cur = self.__head, self.__head.next while cur isnotNone: if cur.val == val: pre.next = cur.next returnTrue else: pre = cur cur = cur.next print('not find %s' % str(val)) returnFalse defdel_pos(self, pos:int)->bool: """ 删除指定pos的结点 与【不带头结点】的单链表对比,不用特殊处理首结点(pos==0)的删除 只是索引从-1开始,其他的部分不变 """ if pos < 0or pos > self.size()-1: print('failed! insert pos out of range!') if self.__head.nextisNone: print('empty link-list!') returnFalse else: i, cur = -1, self.__head while cur.nextisnotNoneand i < pos-1: cur = cur.next i+=1 cur.next = cur.next.next returnTrue
############### 【改】############### defchange(self, pos: int, val) -> bool: '''根据位置改变值''' if pos < 0or pos > self.size()-1: print("change pos out of range!") if self.is_empty(): print('the linklist is empty!') returnFalse else: i, cur = -1, self.__head # 循环结束后, cur指向pos的位置 while cur.nextisnotNoneand i < pos: i += 1 cur = cur.next cur.val = val returnTrue
############### 【查】############### deffind(self, val): '''依据值来定位位置(索引)''' i, cur = -1, self.__head while cur.nextisnotNone: cur = cur.next i += 1 if cur.val == val: return i print('not find %s' % str(val)) returnFalse
deflocate(self, pos: int): '''依据索引查找值''' if pos < 0or pos > self.size()-1: print("out of range!") if self.is_empty(): print('the linklist is empty!') returnFalse else: i, cur = -1, self.__head # 循环结束后, cur指向pos的位置 while cur.nextisnotNoneand i < pos: i += 1 cur = cur.next return cur.val
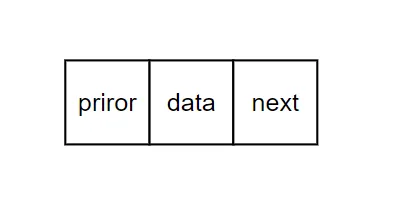
defappend(self, val) -> bool: '''尾插法''' node, cur = D_Node(val), self.__head # 这里就需要先判断是否为空,否则None.next会报错 if cur isNone: self.__head = node returnTrue else: # 循环结束后,cur指向最后一个数据结点 while cur.nextisnotNone: cur = cur.next cur.next = node node.prior = cur returnTrue definsert(self, pos, val) -> bool: '''随机位置插入''' # 先确保传入的pos属于[0, size] if pos < 0or pos > self.size(): print("insert pos out of range!") returnFalse else: if pos == 0: return self.add(val) else: node = D_Node(val) i, cur = 0, self.__head # 循环结束后, cur指向pos-1的位置,因为pos的位置要留给node while cur.nextisnotNoneand i < pos-1: cur = cur.next i += 1 # print('i:',i,end='->') # print(cur.val) node.next = cur.next cur.next = node node.prior = cur if node.nextisnotNone: node.next.prior = node returnTrue
############### 【删】############### '''删除元素的操作也要记得重置prior''' defremove(self, val) -> bool: '''根据值来删除第一个符合条件的结点''' if self.is_empty(): print("the linklist is empty!") returnFalse
pre, cur = None, self.__head # 这里的 pre 完全可以用 cur.prior 来表示,我懒得改了 while cur isnotNone: if cur.val == val: # 先要判断是否删除的是首结点 if cur == self.__head: # 更新首结点 self.__head = self.__head.next # 判断更新后的 self.__head 是否为空 if self.__head isnotNone: self.__head.prior = cur.prior cur = self.__head returnTrue else: pre.next = cur.next # 判断 cur.next 是否为空 if cur.nextisnotNone: cur.next.prior = pre cur = pre.next returnTrue else: pre = cur cur = cur.next returnFalse
defdel_pos(self, pos) -> bool: '''根据位置来指定删除''' if pos < 0or pos > self.size()-1: print("del pos out of range!") if self.is_empty(): print('the linklist is empty!') returnFalse else: # 先要判断是否删除的是首结点 if pos == 0: # 更新首结点 self.__head = self.__head.next # 判断更新后的 self.__head 是否为空 if self.__head isnotNone: self.__head.prior = None returnTrue else: i = 0 # 这里的 pre 完全可以用 cur.prior 来表示,我懒得改了 pre, cur = None, self.__head # 循环结束后, cur指向pos的位置 while cur.nextisnotNoneand i < pos: pre = cur cur = cur.next i += 1 pre.next = cur.next if cur.nextisnotNone: cur.next.prior = pre returnTrue
############### 【改】############### '''改元素值不涉及重连,所以与单链表一样''' defchange(self, pos: int, val) -> bool: '''根据位置改变值''' if pos < 0or pos > self.size()-1: print("change pos out of range!") if self.is_empty(): print('the linklist is empty!') returnFalse else: i, cur = 0, self.__head # 循环结束后, cur指向pos的位置 while cur.nextisnotNoneand i < pos: i += 1 cur = cur.next cur.val = val returnTrue
############### 【查】############### '''改元素值不涉及重连,所以与单链表一样''' deffind(self, val): '''依据值来定位位置(索引)''' i, cur = 0, self.__head while cur isnotNone: if cur.val == val: return i else: i += 1 cur = cur.next print('not find %s' % str(val)) returnFalse
deflocate(self, pos: int): '''依据索引查找值''' if pos < 0or pos > self.size()-1: print("out of range!") if self.is_empty(): print('the linklist is empty!') returnFalse else: i, cur = 0, self.__head # 循环结束后, cur指向pos的位置 while cur.nextisnotNoneand i < pos: i += 1 cur = cur.next return cur.val
defget_random_init(self, n=0): for k inrange(n): self.append(random.randint(0, 10))
defis_empty(self): """判断链表是否为空""" return self.__head isNone defsize(self)->int: if self.is_empty(): return0 cnt, cur = 1, self.__head while cur.next != self.__head: cur = cur.next cnt +=1 return cnt
deftravel(self): if self.is_empty(): print('None') cur = self.__head print(cur.val, end='->')
while cur.next != self.__head: cur = cur.next print(cur.val, end='->') print('None') ###############【增】############### defadd(self, val): node = Node(val) if self.is_empty(): self.__head = node # 循环链表要记得尾部也指向head node.next = self.__head returnTrue else: node.next = self.__head cur = self.__head # 循环结束后,cur到链表尾部 while cur.next != self.__head: cur = cur.next # 将尾部的next指向node, 并将node更新为新的head cur.next = node self.__head = node returnTrue
defappend(self, val) -> bool: '''尾插法''' node, cur = Node(val), self.__head # 这里就需要先判断是否为空,否则None.next会报错 if cur isNone: self.__head = node # 循环链表要记得尾部也指向head node.next = self.__head returnTrue else: # 循环结束后,cur指向最后一个数据结点 while cur.next != self.__head: cur = cur.next cur.next = node # 将node后继指向 head node.next = self.__head returnTrue definsert(self, pos, val) -> bool: '''随机位置插入''' # 先确保传入的pos属于[0, size] if pos < 0or pos > self.size(): print("insert pos out of range!") returnFalse else: if pos == 0: return self.add(val) else: node = Node(val) i, cur = 0, self.__head # 循环结束后, cur指向pos-1的位置,因为pos的位置要留给node while cur.next != self.__head and i < pos-1: cur = cur.next i += 1 # print('i:',i,end='->') # print(cur.val) node.next = cur.next cur.next = node returnTrue
############### 【删】############### defremove(self, val) -> bool: '''根据值来删除第一个符合条件的结点''' if self.is_empty(): print("the linklist is empty!") returnFalse
cur = self.__head # 先要判断首结点的值是否符合删除条件 if cur.val == val: # 如果链表只有一个结点 if cur.next == self.__head: self.__head = None returnTrue else: # 循环结束后cur指向最后一个结点 while cur.next != self.__head: cur = cur.next # 将尾部与新的首结点连起来 cur.next = self.__head.next self.__head = self.__head.next returnTrue
else: # 说明首结点的值不符合 pre, cur = self.__head, self.__head.next while cur != self.__head: if cur.val == val: pre.next = cur.next returnTrue else: pre = cur cur = cur.next print('not find %s ' % str(val)) returnFalse
defdel_pos(self, pos) -> bool: '''根据位置来指定删除''' if pos < 0or pos > self.size()-1: print("del pos out of range!") if self.is_empty(): print('the linklist is empty!') returnFalse else: # 先要判断是否删除的是首结点 if pos == 0: cur = self.__head # 如果链表只有一个结点 if cur.next == self.__head: self.__head = None returnTrue else: # 循环结束后cur指向最后一个结点 while cur.next != self.__head: cur = cur.next #print('end val:', cur.val) # 将尾部与新的首结点连起来 cur.next = self.__head.next self.__head = self.__head.next returnTrue
else: i = 1 pre, cur = self.__head, self.__head.next # 循环结束后, cur指向pos的位置 while cur != self.__head and i < pos: pre = cur cur = cur.next i += 1 pre.next = cur.next returnTrue
############### 【改】############### defchange(self, pos: int, val) -> bool: '''根据位置改变值''' if pos < 0or pos > self.size()-1: print("change pos out of range!") if self.is_empty(): print('the linklist is empty!') returnFalse else: i, cur = 0, self.__head # 循环结束后, cur指向pos的位置 while cur.next != self.__head and i < pos: i += 1 cur = cur.next cur.val = val returnTrue
############### 【查】############### deffind(self, val): '''依据值来定位位置(索引)''' if self.is_empty(): print('the linklist is empty!') returnFalse if self.__head.val == val: return0 else: i, cur = 1, self.__head.next while cur != self.__head: if cur.val == val: return i else: i += 1 cur = cur.next print('not find %s' % str(val)) returnFalse
deflocate(self, pos: int): '''依据索引查找值''' if pos < 0or pos > self.size()-1: print("out of range!") if self.is_empty(): print('the linklist is empty!') returnFalse else: i, cur = 0, self.__head # 循环结束后, cur指向pos的位置 while cur.next != self.__head and i < pos: i += 1 cur = cur.next return cur.val
6.1.4 链表逆序
链表逆序就是把一个链表的尾变头,头变尾。属于链表中的经典问题。
6.1.4.1 方案一
将第二个结点后面的元素依次插入到第一个结点后面, 这个方法对于带不带头结点的链表都适用。 举例 ① 不带头结点的链表 原始链表,其中第二个元素是 B A -> B-> ==C== -> D -> E -> F -> null 先进入循环,不断的把B的后继元素往第一个元素后面插 A -> C -> B -> ==D== -> E -> F -> null #将上面 B后的 C 插入到A后面 A -> D -> C -> B -> ==E== -> F -> null #将上面 B后的 D 插入到A后面 A -> E -> D -> C -> B -> ==F== -> null #将上面 B后的 E 插入到A后面 A -> F -> E -> D -> C -> B -> null #将上面 B后的 F 插入到A后面 最后将F作为新的首结点,将A放到B后面: F -> E -> D -> C -> B -> A -> null
② 带头结点的链表 可以将头结点视为第一个元素,那么就是直接把 A 的后继元素不断的往head后面插: 带头结点原始链表,将头结点视为第1个元素,那么其中第2个元素是 A Head -> A -> ==B==-> C -> D -> E -> F -> null 先进入循环,不断的把A的后继元素往头结点后面插 Head -> B -> A -> ==C== -> D -> E -> F -> null Head -> C -> B -> A -> ==D== -> E -> F -> null Head -> D -> C -> B -> A -> ==E== -> F -> null Head -> E -> D -> C -> B -> A -> ==F== -> null Head -> F -> E -> D -> C -> B -> A -> null
defreverse(self, head): pre, cur = None, head while cur: # 先保存剩余部分的头 rest = cur.next # 当前结点指向前面 cur.next = pre # pre指针移动到当前结点 pre = cur # cur指针指向剩下部分的头 cur = rest return pre
6.1.4.3 方案三
采用递归的思路
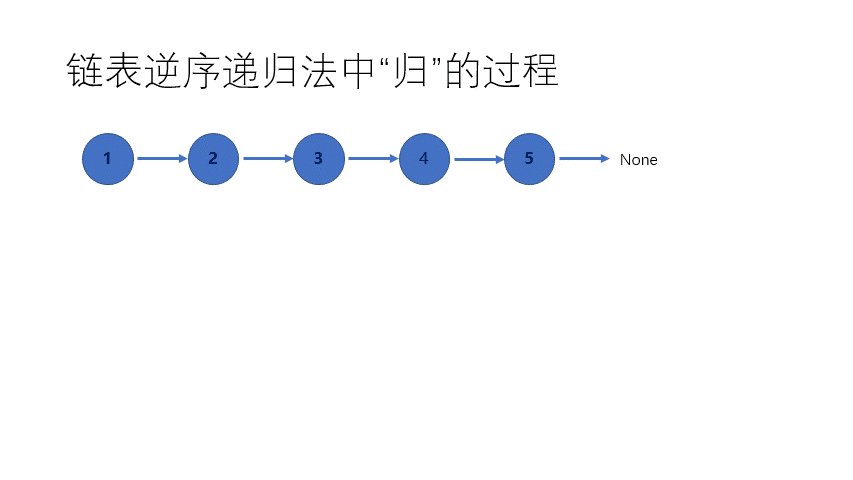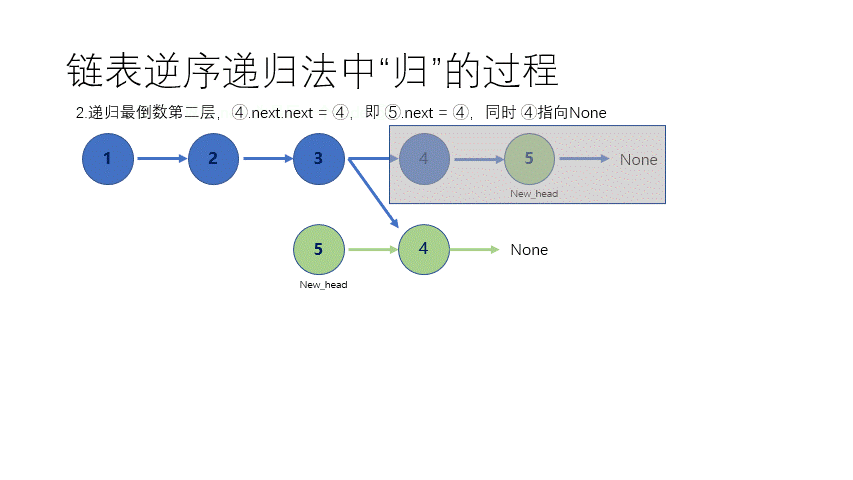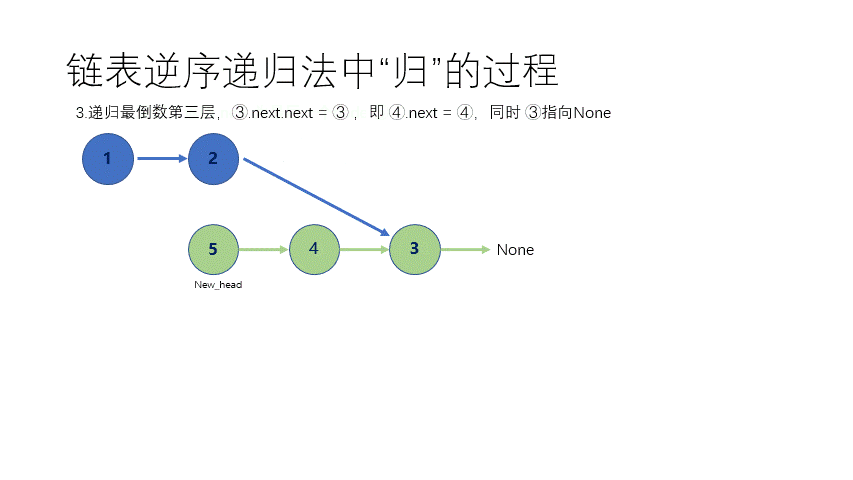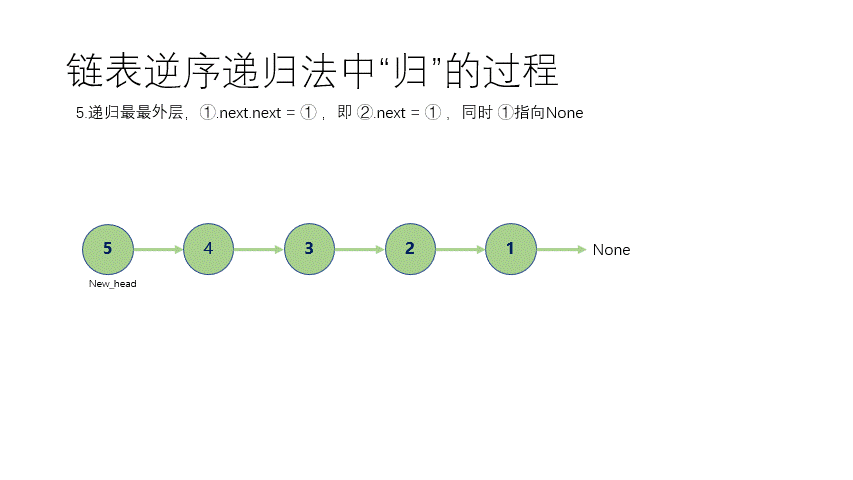
① 不带头结点 递归其实就是一直要找到最后一个结点,然后每次改一下。 这个时候其实 函数递归的时,函数用系统栈存储了前面每个结点的信息,所以一步一步从最后面改动到前面去,最后返回了一个以原始尾结点的地址为头指针的 无头结点单链表。