
5 随机失活

深度学习系列博文目录一览
————————————————
5 随机失活
5.1 模型平均
如果对传统机器学习有所了解的话,会知道有一种称之为集成学习的方法。
而神经网络中的随机失活-dropout其实就是借鉴了集成学习的思想,更具体地,是集成学习中的bagging方法,即模型平均思想的一种运用。
因为模型平均要对训练集有放回的采样,得到多个不同的训练集,再训练多个不同的模型,
在测试阶段由多个不同的模型投票表决或者平均 来做出最终预测。
但是对于深度神经网络而言,训练多个不同的模型 可能不切实际,会耗费大量时间和计算力。
5.2 dropout作用关于模型平均的解释
dropout 对神经元随机失活,也就是说前传的过程中可能这个神经元以及它后面的路径并不会被使用,相当于前传的路径只是整个大神经网络的一个子网络。</font>
所以训练的时候,相当于是在并行训练很多个子网络(模型);
预测的时候,随机失活不产生作用,这样使用 的就是整个大网络模型,得到的结果相当于是综合考虑子网络得到的平均结果。
这样就相当于实现了bagging训练。
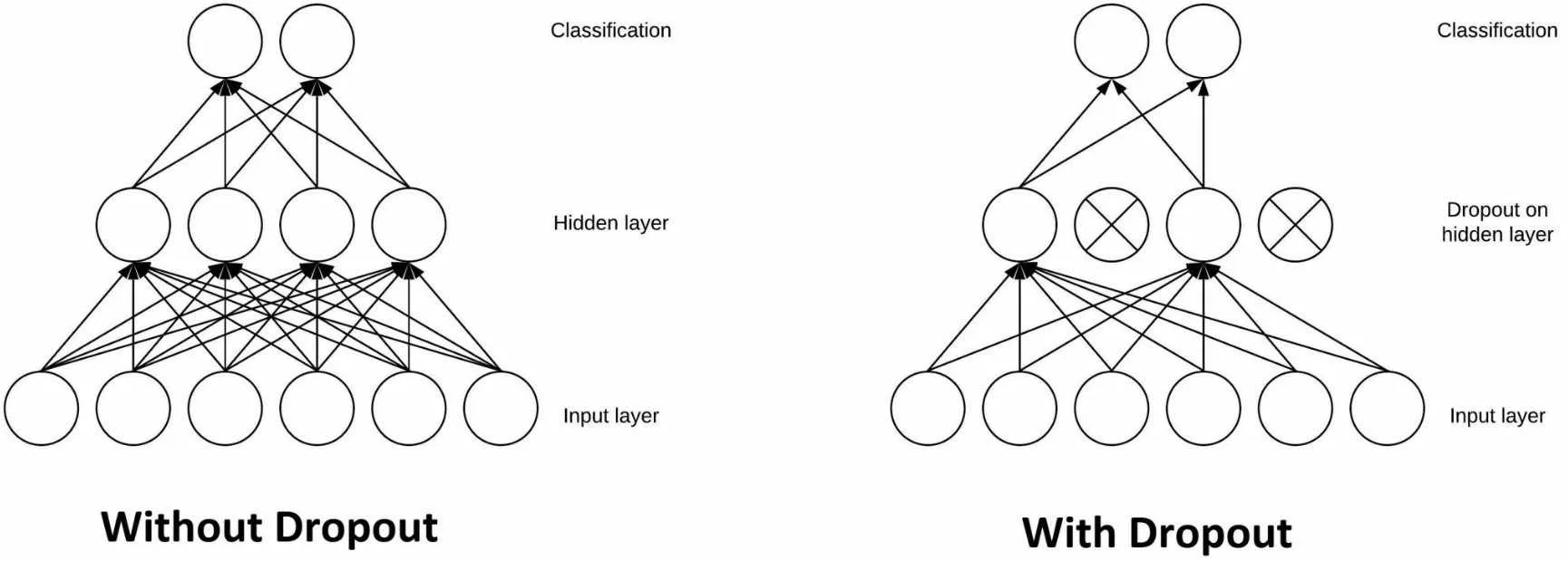
Dropout训练与Bagging训练的一些区别。
- ①
在Bagging的情况下,所有模型都是独立;
在Dropout的情况下,所有模型共享参数,其中每个模型继承父神经网络参数的不同子集。其中每个参数共享使得在有限可用的内存下表示指数级数量的模型变得可能。
②
在Bagging的情况下,每一个模型在其相应训练集上训练到收敛。在Dropout的情况下,通常大部分模型都没有显式地被训练,因为通常父神经网络会很大,以致于到宇宙毁灭都不可能采样完所有的子网络。取而代之的是,在单个步骤中我们训练一小部分的子网络,参数共享会使得剩余的子网络也能有好的参数设定。
这些是仅有的区别。除了这些,Dropout与Bagging算法一样。
每一个随机失活的单元都可以设置一个失活概率P,是超参数,控制前向传播的时候,dropout是否发生作用。
5.2 dropout作用关于正则化的解释
在后续的研究中,研究者发现dropout可能不是Hinton认为的那样是类似于bagging训练,也就是说我们上面的解释可能只是Hinton当时的一种初级解释。现在学界普遍认为,dropout是引入了噪音,相当于对网络引入了正则项。


